


Featured
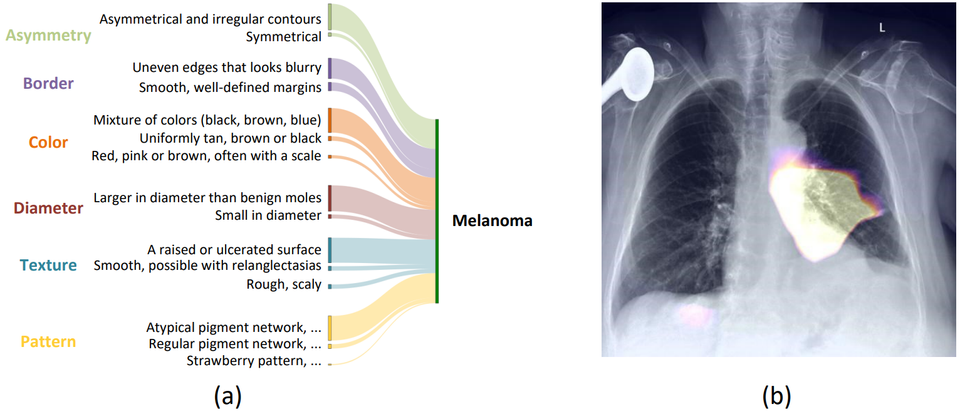
Interpretable Medical Image Diagnosis with Explicd

Derm-T2IM: Harnessing Synthetic Skin Lesion Data via Stable Diffusion Models for Enhanced Skin Disease Classification using ViT and CNN

ViTPose : A simple yet powerful transformer baseline for Human Pose Estimation

FreqyWM:
The Skin Game: Setting New Standards for AI in Dermatology

Prompt Depth Anything

Uncertainty Quantification for skin cancer classification using Bayesian Deep Learning

Revolutionizing Cancer Diagnosis with the CHIEF Foundation Model
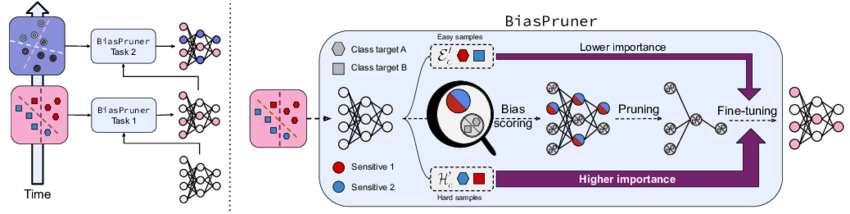
BiasPruner: Debiased Continual Learning for Medical Image Classification

StoryMaker
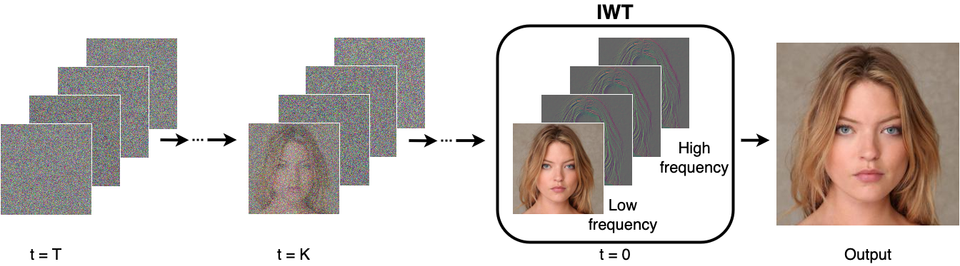
Wavelet Diffusion Models are fast and scalable Image Generators

S-SYNTH : Knowledge-based synthetic generation of skin images

Sapiens: Foundation for Human Vision Models
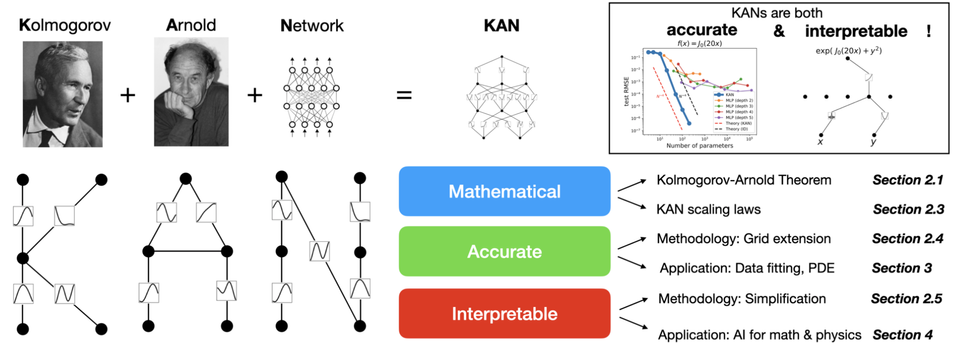
Exploring Kolmogorov-Arnold Networks (KANs)
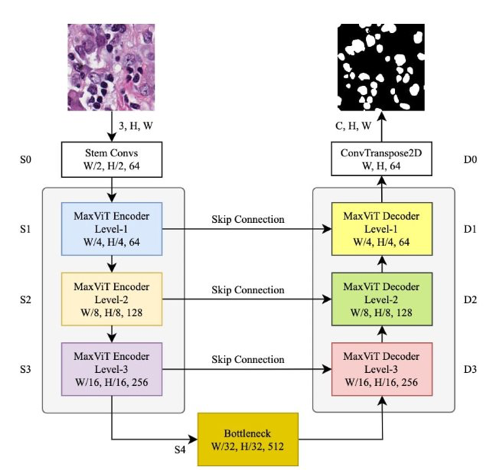
MAXVIT-UNET: MULTI-AXIS ATTENTION FOR MEDICAL IMAGE SEGMENTATION

Ugly duckling detection using deep learning
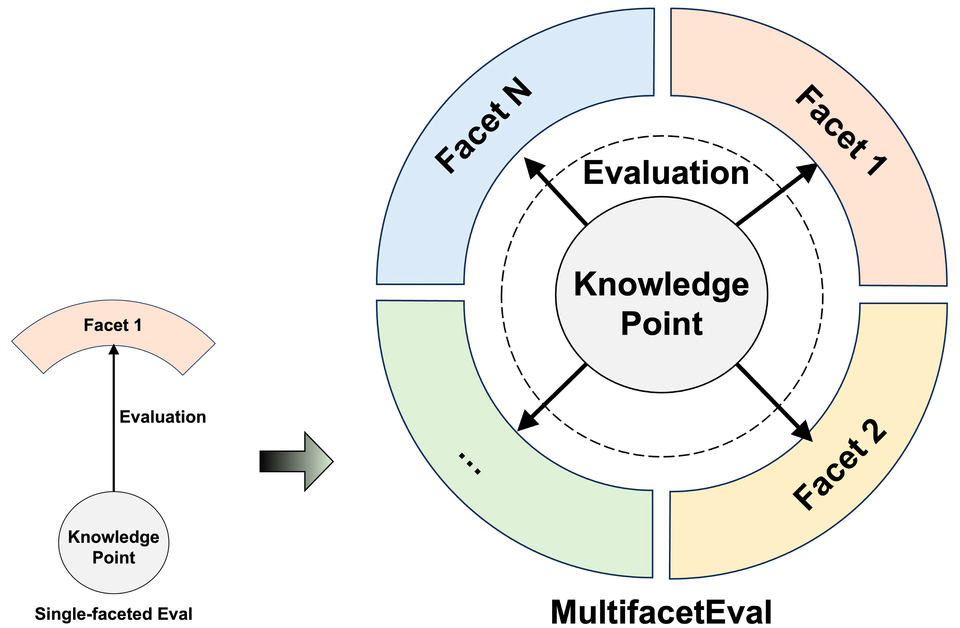
MultiFacetEval

SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery

ReNoise
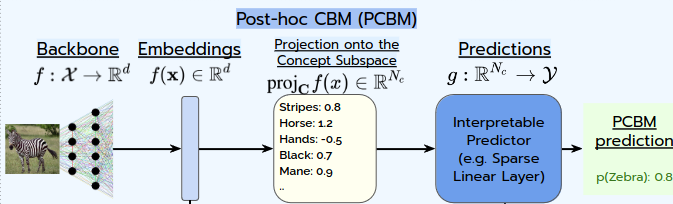
Post-Hoc Concept Bottleneck Models
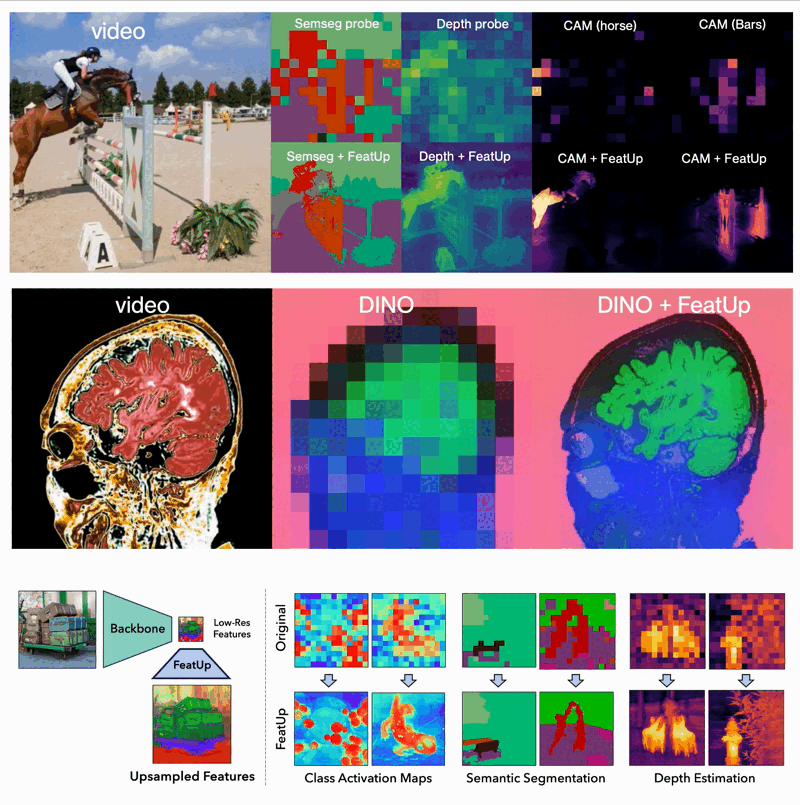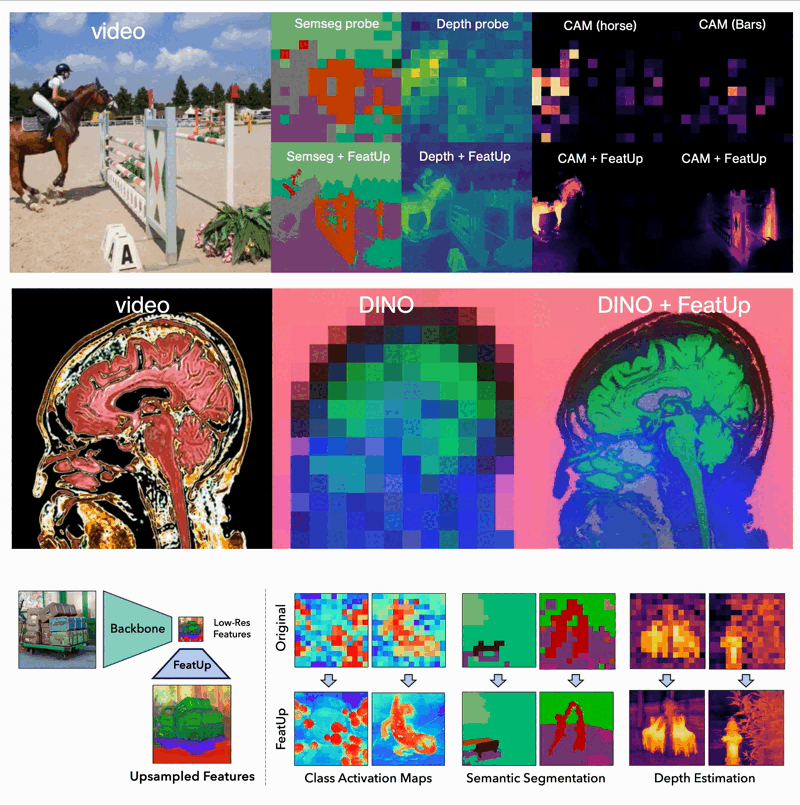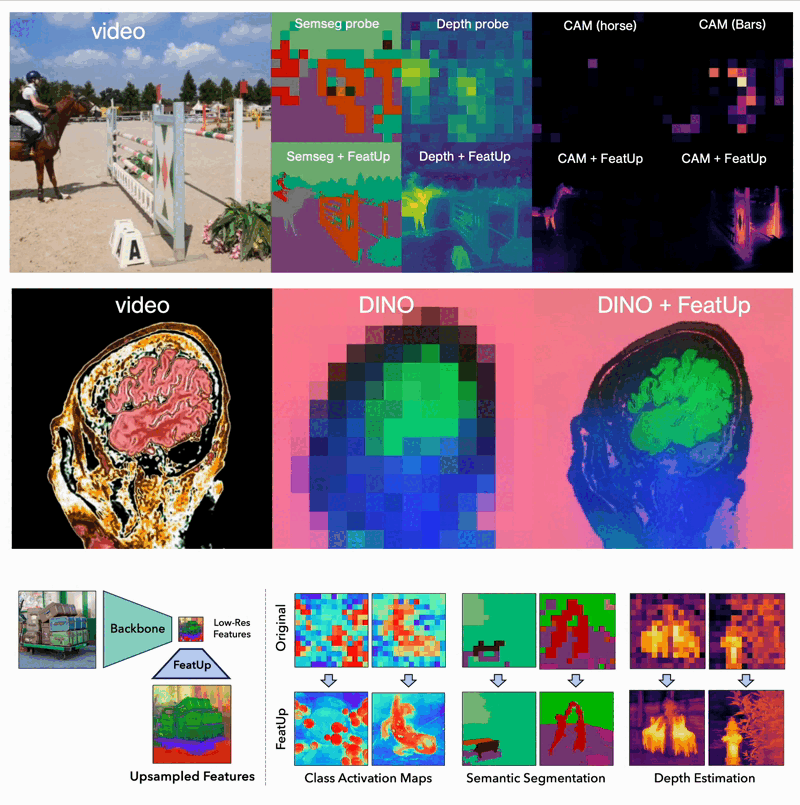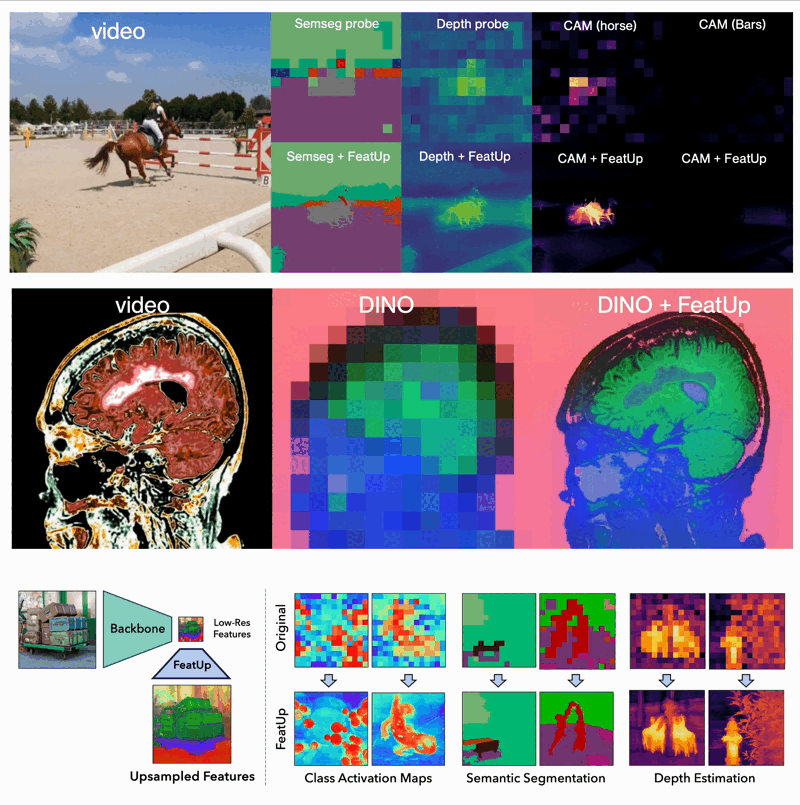
FeatUp: A Model-Agnostic Framework for Features at Any Resolution

Recently in AI | April 2024
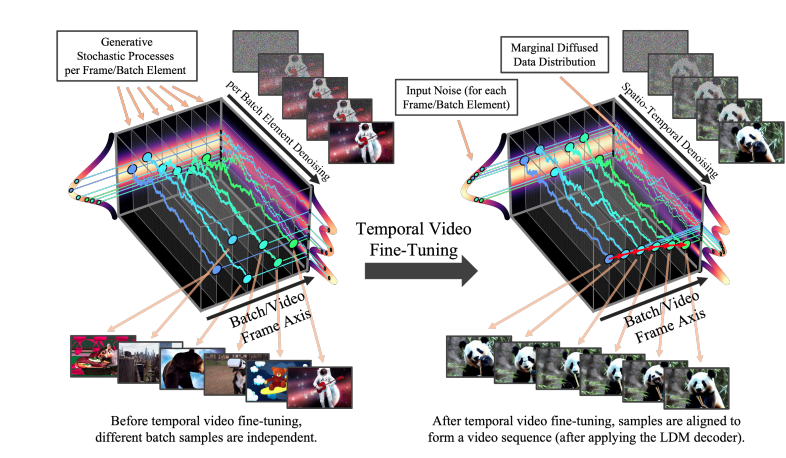
High-Resolution Video Synthesis with Latent Diffusion Models
Catmull-Clark's algorithm

Face aging with Identity-preserved CGANs.

LRM : Large Reconstruction Model for Single Image to 3D

Depth Anything

Unveiling SAM: Revolutionizing Image Segmentation with the Segment Anything Model

Data Augmentation in Classification and Segmentation: A Survey and New Strategies

Understanding DLSS: A Dive into NVIDIA's Revolutionary Technology
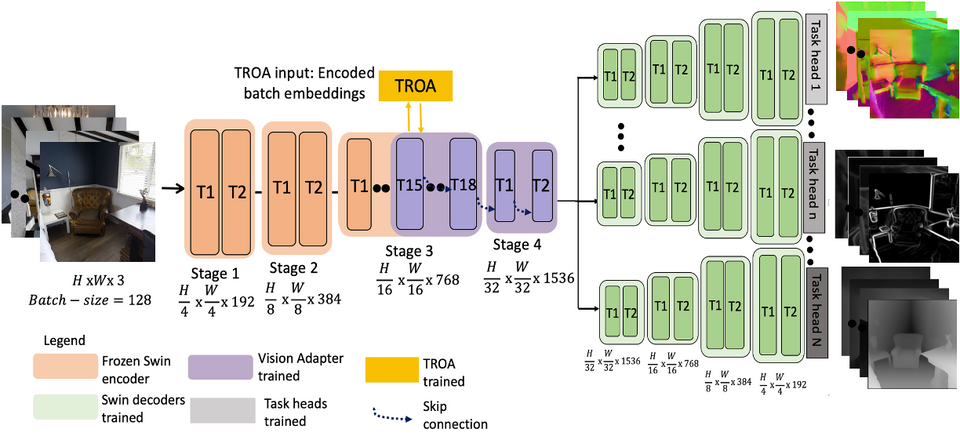
“Vision Transformer Adapters for Generalizable Multitask Learning”

Can AI do Math Research ?
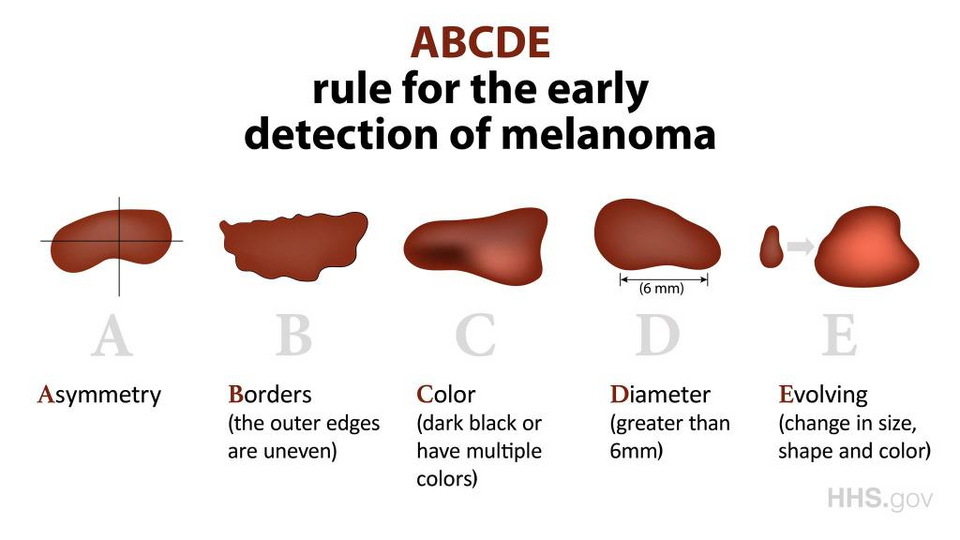
Unmasking Skin Lesions

Skeleton project with DWPose

Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation

Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion
Computed tomography scan
A step into Machine Unlearning
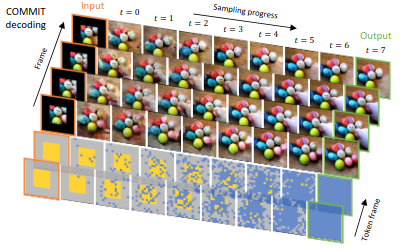
"MAGVIT: Masked Generative Video Transformer"

Supercharge Your Python Code with a Comprehensive Testing Strategy
Mastering Generative AI with Large Language Models

Exploring Image Similarity Search and Deduplication
Dynamical Systems & machine Learning
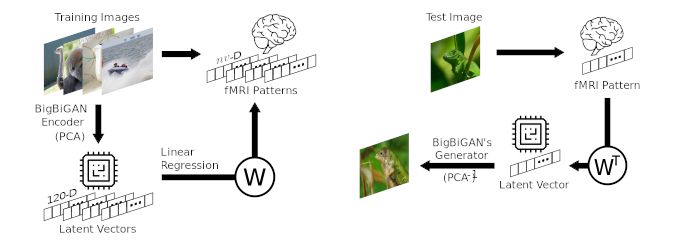
Reconstructing Natural Scenes from fMRI Patters Using Deep Generative Networks

“Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture”, the latest paper from Yann Lecun’s team at Meta

DeepXplore: Unleashing the Power of Automated Whitebox Testing for Deep Learning Systems
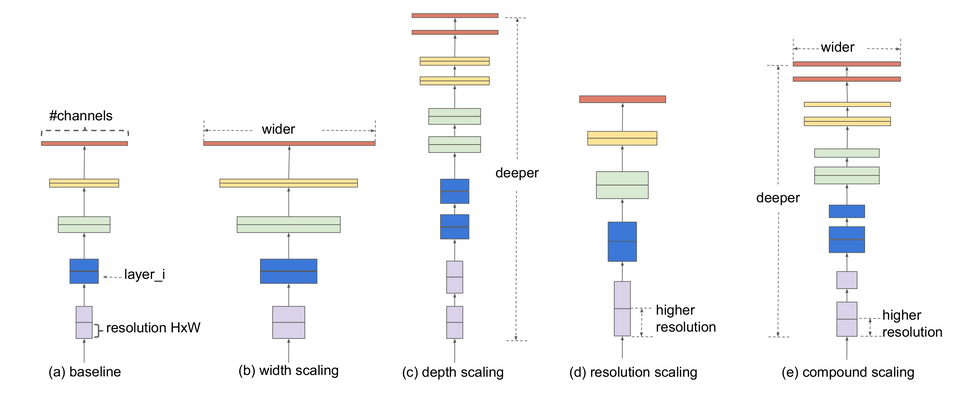
EfficientNetV2: Smaller Models & Faster Training

Depth Map
Unsupervised Learning in Spiking Neural Networks

SkinGAN Project using LaMa-Fourier

Overview of Self Supervised Learning

SAM: Segment Anything Model by Meta AI
Introduction aux Graphes Neural Networks
AI Insights
-
Introduction aux Graphes Neural Networks
-
SAM: Segment Anything Model by Meta AI
-
Overview of Self Supervised Learning
-
SkinGAN Project using LaMa-Fourier
-
Unsupervised Learning in Spiking Neural Networks
AI Tasting Seminars
-
Reconstructing Natural Scenes from fMRI Patters Using Deep Generative Networks
-
From Dilated Convolution With Learnable Spacings to Gaussian Mixture Kernel Convolution
-
A Bayesian Framework for Multivariate Multifractal Analysis of Signals and Images
-
Functional Principal Component Analysis
-
Training Adaptive Reconstruction Networks for Blind Inverse Problems