
A step into Machine Unlearning
#MachineUnlearning #Forgetting #DataPrivacy
What is Machine Unlearning ?
Basically, this concept represents the opposite of machine learning : it serves to make a model unlearn or forget. Using specific algorithms, applied to previously trained models, we control that the trained models erase specific data point’s contributions from the training dataset. The beginning of machine unlearning results from the "Right to be Forgotten" legislation, a requirement of the European Union's General Data Protection Regulation (GDPR), published in 2016. After the European Union, other countries like Canada, India, and the state of California (USA) followed the path with their own privacy legislations, calling for transparency and clarity of data, and empowering users to remove their private data.

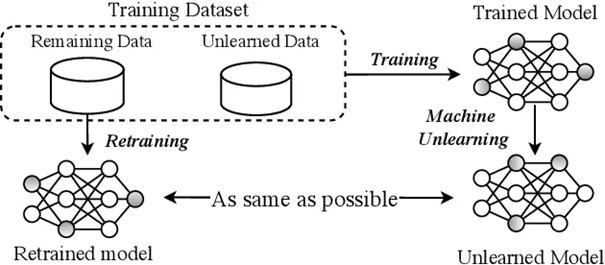
In theory, the best way to forget a portion of data is to retrain the model with the remaining data. But Machine Unlearning is not just retraining a model after a removal request: in terms of time and resource consumption, we need to find more optimal algorithms than the brutal force to remove efficiently the corresponding data. This is the one of the main challenges and active researches of Machine Unlearning.
Why Machine Unlearning is necessary?
- Privacy: Thanks to the new privacy regulations, users can ask for their data to be forgotten from a machine learning system.
- Fidelity: Despite recent advances, machine learning models are still sensitive to bias that means their output can unfairly discriminate against a group of people. The source of these biases often originate from data. For example, AI systems that have been trained on public datasets that contain mostly white people, such as ImageNet, are likely to make errors when processing images of black people. As a result, there is a need to unlearn these data, including the features and affected data items.
- Security: Deep learning models have been shown to be vulnerable to external attacks, especially adversarial attacks. In an adversarial attack, the attacker generates adversarial data that are very similar to the original data to the extent that a human cannot distinguish between the real and fake data, that can make the deep learning models predict wrong outputs. Hence, once an attack is detected, the model needs to be able delete the adversarial data.
- Usability: People have different preferences in online applications and/or services, especially recommender systems. An application will produce inconvenient recommendations if it cannot completely delete the incorrect data (e.g., noise, malicious data, out-of-distribution data) related to a user. Such undesired usability by not forgetting data will not only produce wrong predictions, but also result in less users.
What types of unlearning requests ?
● Item removal: requests to remove certain samples from the training data. They are the most common requests.
● Feature removal : requests to remove a group of data with similar features or labels. It can be useful for example to remove poisoned data from our training set.
● Class removal : requests to remove all data belonging to a specific class. For example, you can request to remove your name from a face recognition system, so the model should remove the class corresponding to your person.
● Task removal : requests to remove a learned task from a multitask machine learning algorithm.
How to make a model to forget ?
There are several techniques to make a model forget, and we will not detail them here. But, the common idea behind these algorithms is to apply to the original model (trained on all the dataset) an unlearning procedure to obtain an unlearned model that has forgotten the portion of data requested. The aim is that this unlearned model should be as similar as possible to the model that has been trained only on the remaining data. However, in practice we don't have access to this model retrained on remaining data.
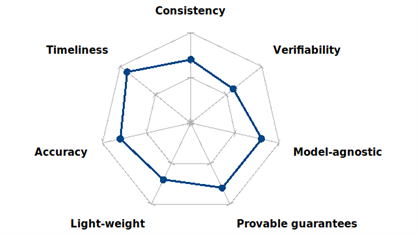
Unlearning algorithm requirements
In order to build an unlearning algorithm, there are some pillars that we need to identify, and then decide the importance of each of them for our use case. All of them are not compatible, so we need to define what the requirements of our algorithm are in order to design it better. Do we want our unlearning procedure to be fast, at the cost of less accuracy and consistency? Do we want our unlearning procedure to be provable, transparent and easy to guarantee, at the cost of being heavier and slower? Answering such questions will lead to a trade-off between these seven different features, which will guide us in choosing which unlearning algorithm best fits our requirements.
Actual challenges in Machine Unlearning
● There is no unique method for all types of unlearning problems and all types of models. Researchers are working in designing more generalizable methods.
● An unlearned model usually performs worse than the model retrained on the remaining data. However, the degradation can be exponential when more data is unlearned: this is what we call catastrophic unlearning. Some works have focus on defining special loss functions and techniques to avoid such problem.
● As an effect of the stochasticity of training, complete unlearning may not always be possible, and residual knowledge or biases may still remain in the model, reduced at maximum if possible.