
Depth Anything

Unleashing the Power of Large-Scale Unlabeled Data
Lihe Yang et al., January 2024
Monocular Depth Estimation (MDE)
The goal is to estimate depth information from a single image (i.e. monocular).
The main application are robotics, autonomous driving, and VR. But it's also been applied to healthcare and could be for skin AI projects.
Some examples of MDE applications
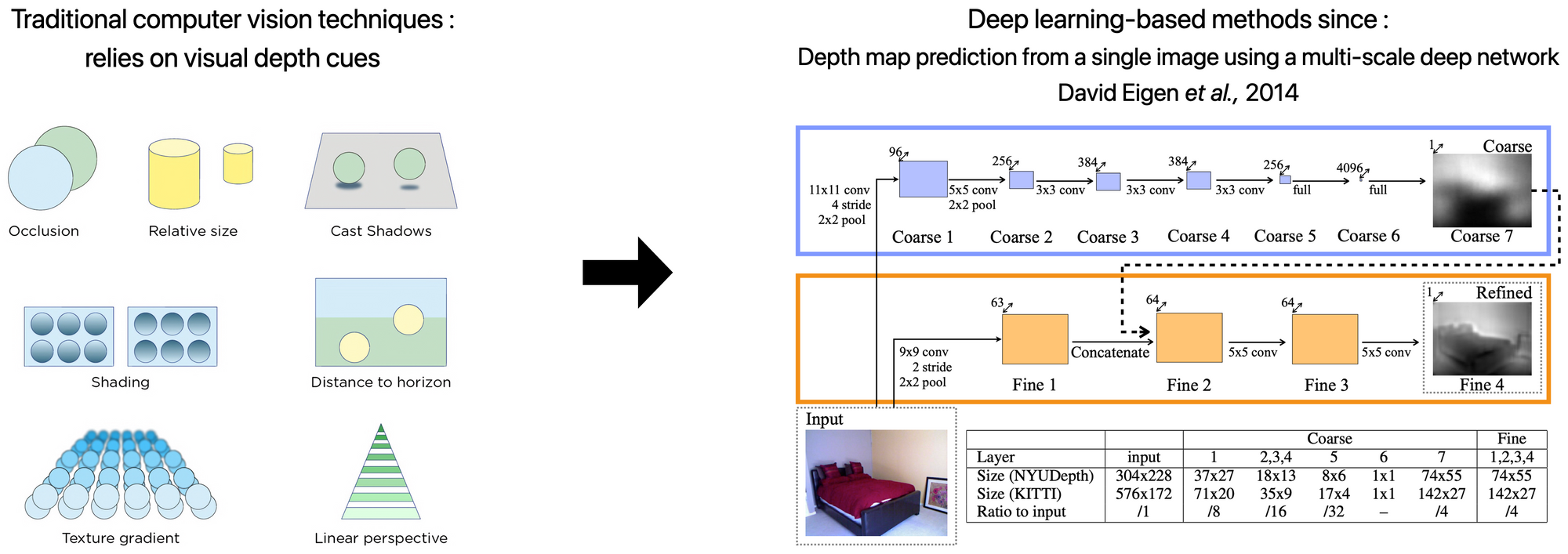
Early works were based on traditional computer vision techniques and handcrafted features. Obviously, when dealing with complex scenes with occlusions and textureless regions, these methods were very limited.
In 2014, Eigen et al. proposed the first deep-learning approach to regress the depth and after this milestone, many works progressively improved the accuracy.
However, despite the promising performance of these methods, there is still an unsolved challenge that is the difficulty to generalize to unseen domains.
Zero-shot depth estimation
To develop a robust MDE model capable of predicting depth for any input image, more data is needed. Traditionally, depth datasets are created mainly by acquiring data from sensors e.g. LIDAR, or using techniques e.g. stereo matching and Structure from Motion (SfM). These methods are expensive, time-consuming, and sometimes impractical. And on top of that, the data coverage is still not enough ...
MiDaS (Mixing datasets for zero-shot cross-dataset transfer, R. Ranftl et al., 2020) is a recent work that consists on training a MDE model on a collection of mixed labeled datasets. To enable effective multi-dataset joint training, it uses an affine-invariant loss to ignore the different depth scales and shifts across the datasets. Thus, MiDaS provides relative depth information and it is possible to get metric depth estimation with fine-tuning, as demonstrated by ZoeDepth.
Despite demonstrating a certain level of zero-shot ability, MiDaS is limited by its data coverage, thus disastrous performance in some scenarios.
Depth Anything follows MiDaS ideas and improves the robustness by using a large-scale unlabeled dataset.
Depth Anything overview

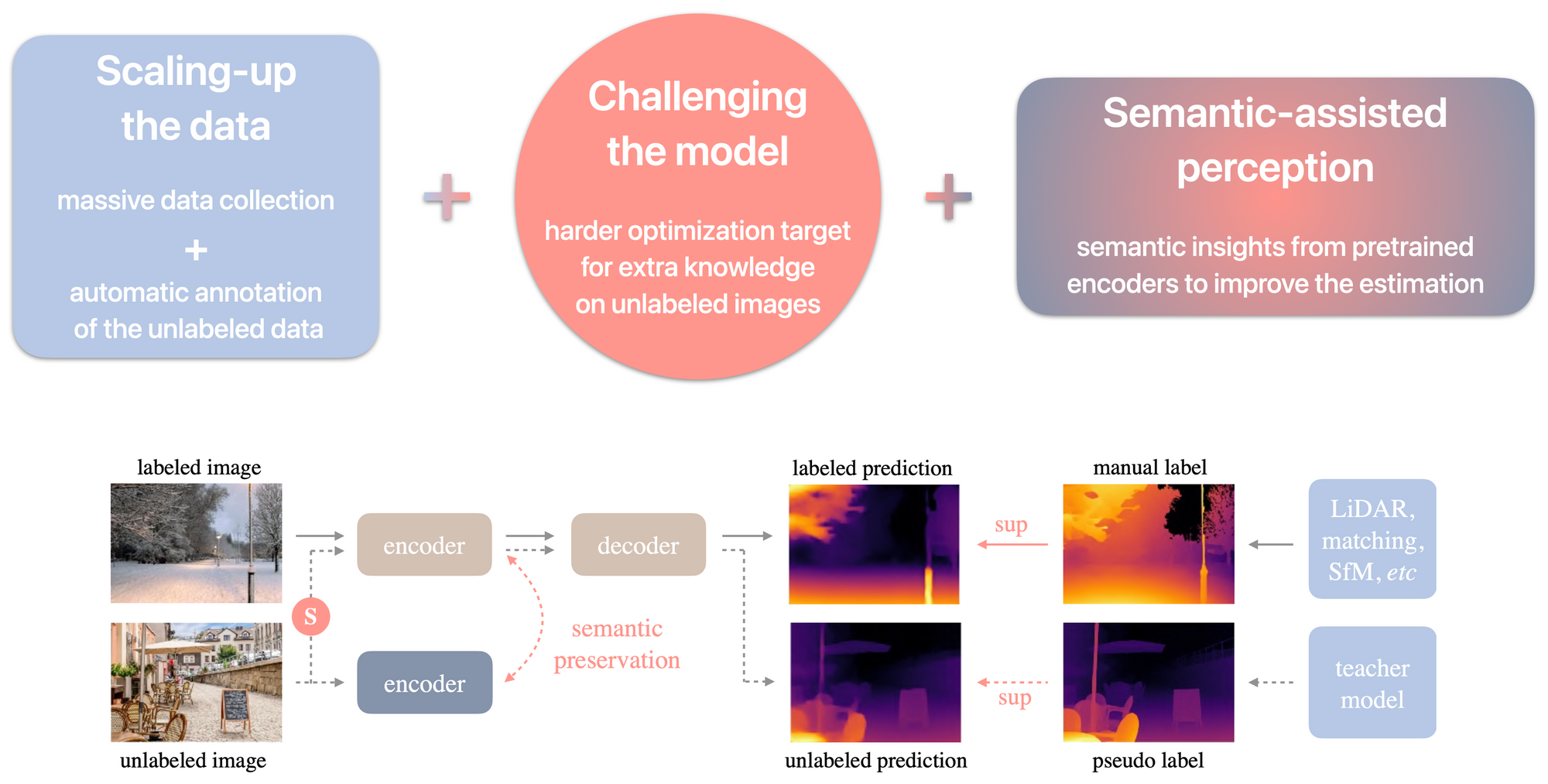
1. Scaling-up the data
For the data acquisition, the authors collected ~62M diverse unlabeled images from 8 public datasets and ~1.5M labeled images from 6 public datasets to train a teacher MDE model as a reliable annotation tool for the unlabeled images.
Data acquisition and coverage
Here are the components of this model (please click on the image to enlarge it).

2. Challenging the model
A student MDE model is trained on the combination of the labeled dataset and the pseudo-labeled dataset. Since there was no improvement with a such self-training pipeline, the authors proposed to challenge the student by making it seek extra visual knowledge on the pseudo-labeled dataset. Two types of strong perturbations are injected to the pseudo-labeled dataset during the training : colour (e.g. jittering and Gaussian blurring) and spatial (CutMix, with 50% chance)
A loss for the pseudo-labeled set, adapted for CutMix is used to train the student and eventually, that makes the large-scale pseudo-labeled images significantly improve the baseline of labeled images.
3. Semantic-assisted perception
The goal is to improve the depth estimation with an auxiliary segmentation task, following some works e.g. this one. In the specific context of leveraging unlabeled images, this auxiliary supervision from another task can also combat the potential noise in the pseudo labels. Since DINOv2 models in semantic segmentation have strong performance, even with frozen weights without fine-tuning, Depth Anything proposes to transfer the DINOv2 semantic capability to the student model. Besides, in this way, the feature space is high-dimensional and continuous and thus contains richer semantic information than discrete masks.
The auxiliary feature alignment loss is defined as :
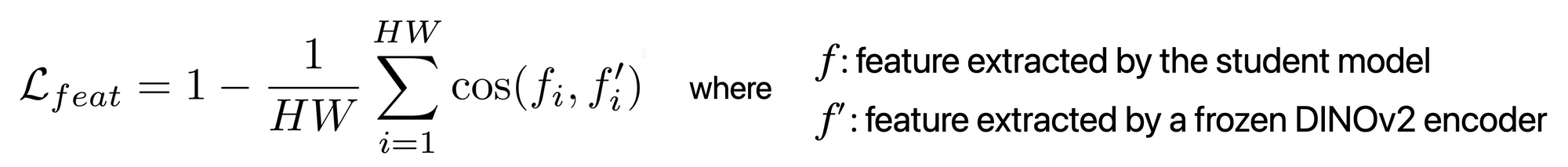
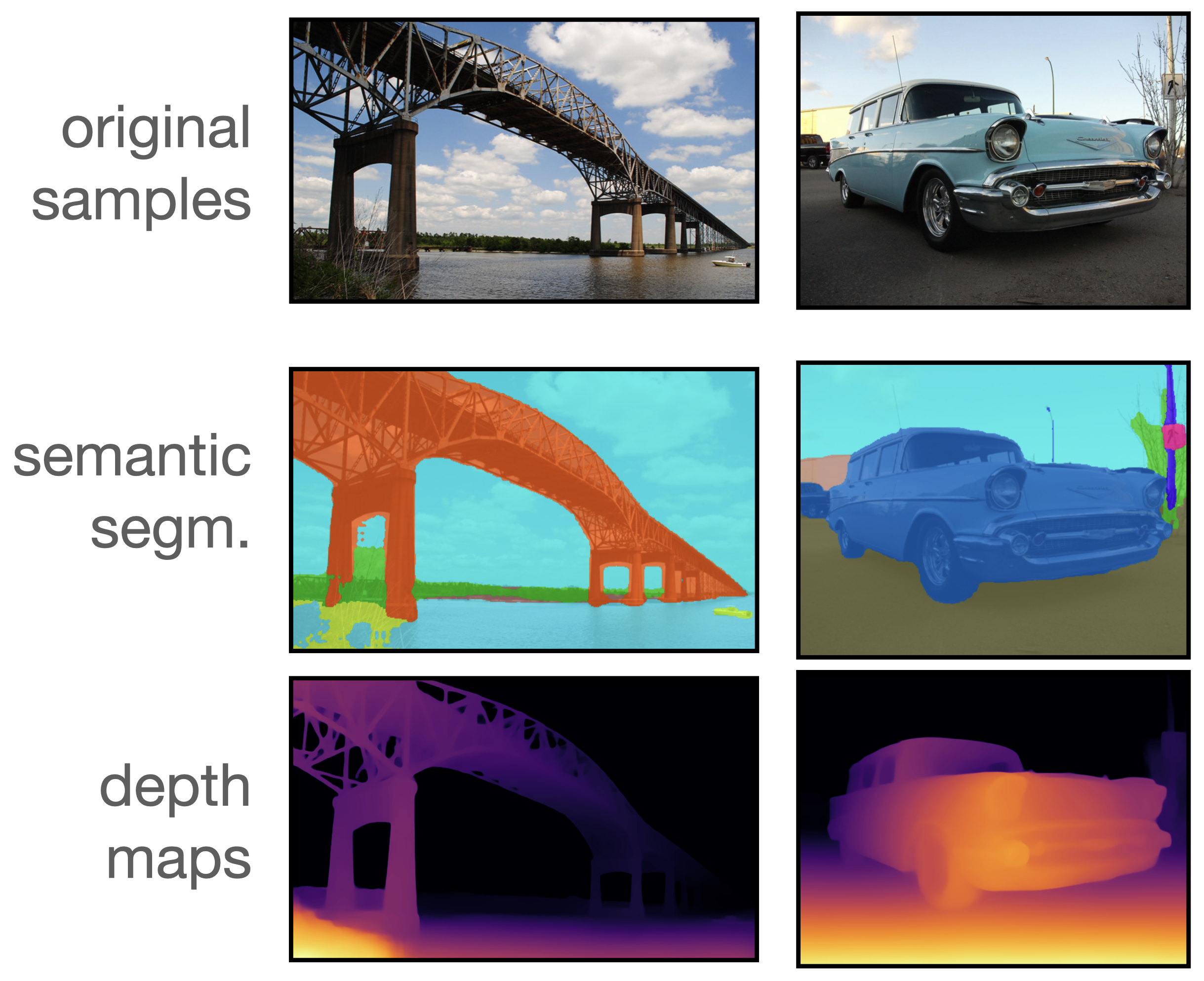
Also, a tolerance margin is used to avoid the depth model to produce exactly the same features as the semantic encoder, as explained in the image below :
Benchmarks and performance
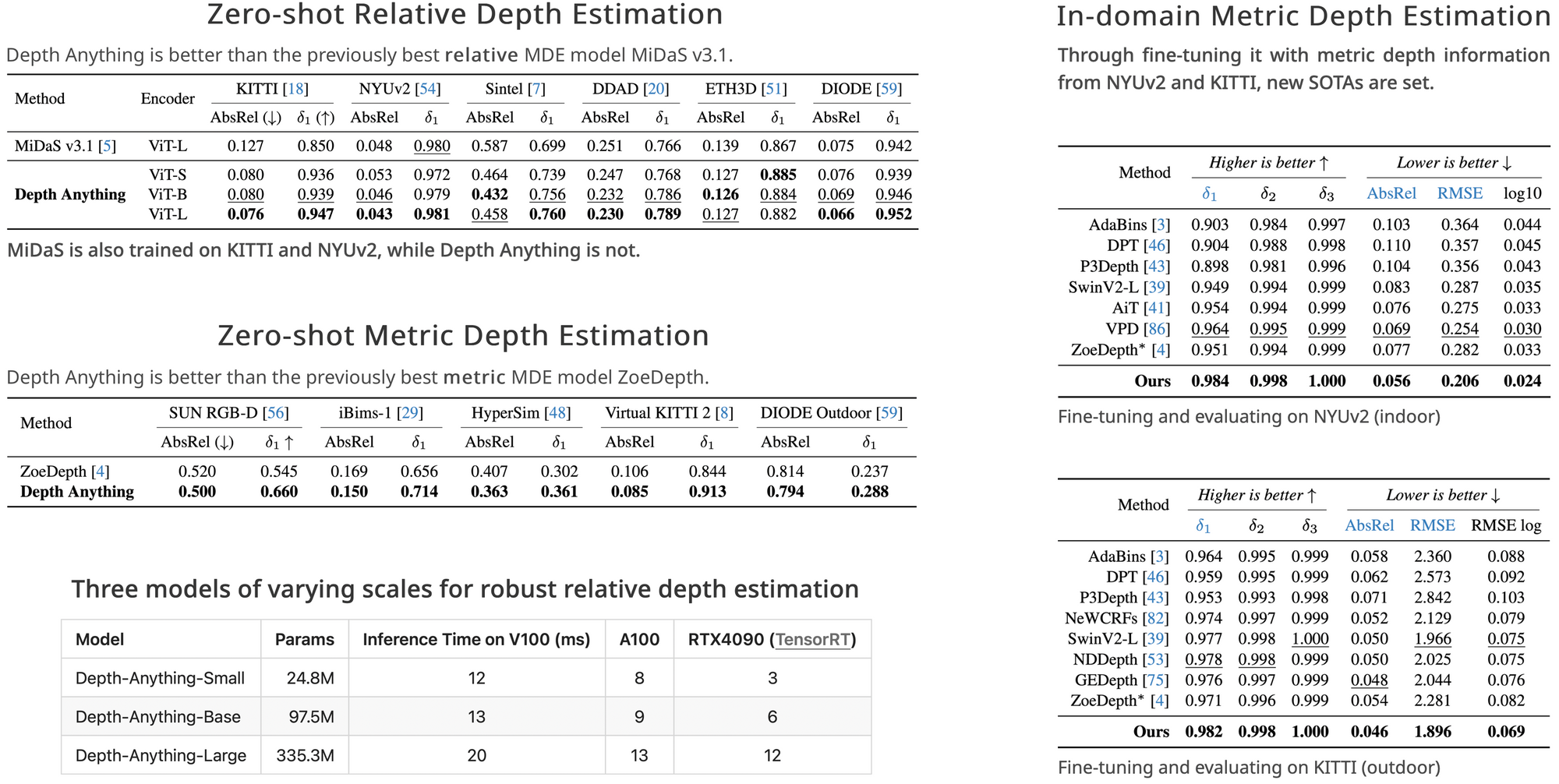
Comparison with the most advanced MiDaS v3.1 (July 2023)



Qualitative results on : 1. KITTI, 2. NYUv2 (MiDaS is trained on these both datasets, while DA is not), 3. Sintel
References
- Depth Anything : paper, web page, code, demo
- DINOv2 : web page, blog post
- MiDaS : paper, v3.1 paper, code, PyTorch page


Member discussion