
Exploring Image Similarity Search and Deduplication

Introduction
In this blog post, we will briefly touch upon the practical applications and techniques of image similarity search. While it is an indispensable tool for optimizing workflows and boosting efficiency in Data Science, we will only scratch the surface of this topic. This blog post is only meant as a starting point into this topic.
In the realm of Data Science, where large amounts of visual data are processed and analyzed, the ability to quickly identify similar images is crucial. Whether you're training neural networks, building image recognition models, or working on recommender systems, image similarity search can significantly improve your workflow for multiple reasons.
Image similarity
Image similarity search is a technique used to find images that are visually similar to a given query image. It involves comparing the visual features of images to identify those that share similar characteristics. This can be done using various methods, including deep learning.
With image similarity search, we can perform several tasks:
- Exploratory Data Analysis (EDA): By finding visually similar images, we can gain insights into the structure and patterns within a dataset. This can help in understanding the distribution of images, identifying clusters, or discovering outliers.
- Deduplication: Image similarity search can be used to identify duplicate or near-duplicate images within a collection. This is useful for removing redundant images, optimizing storage, or ensuring uniqueness in image databases.
- Visual Recommendation Systems: By finding visually similar images, we can build recommendation systems that suggest related content or products. For example, in e-commerce, it can recommend similar items based on a user's preferences or suggest visually related images in a photo-sharing platform.
Image deduplication
Deduplication, in the context of data science, refers to the process of identifying and removing duplicate or near-duplicate records from a dataset. It involves comparing the data entries and determining which ones are redundant or highly similar.
In a Data Science project, performing deduplication is crucial for several reasons:
- Data Quality: Duplicate records can significantly impact the quality and integrity of a dataset. They can introduce inconsistencies, errors, and inaccuracies in the analysis or modeling process. By removing duplicates, data scientists can ensure the reliability and accuracy of their analyses.
- Storage Optimization: Duplicate records consume unnecessary storage space. This becomes especially important when dealing with large datasets or limited storage resources. Deduplication helps optimize storage by removing redundant data, resulting in more efficient data management and a lower storage cost.
- Improved Analysis and Modeling: Duplicate records can skew statistical analyses, machine learning models, and other data-driven algorithms. They can lead to biased results, overfitting, or inflated performance metrics. By eliminating duplicates, data scientists can obtain more reliable and representative insights from their data.
Techniques
In the field of image similarity search, various techniques have been developed to enable efficient and accurate retrieval of similar images. In this blog post we will talk about 3 techniques : metadata approaches, perceptual hashes approaches, and deep learning approaches. Each approach offers its own set of advantages and disadvantages, catering to different requirements and constraints.

Metadata approach
In this approach, images are associated with metadata such as tags, descriptions, or keywords. The similarity between images is determined by filtering all images that contains your selected set of metadata keywords. This approach is relatively simple and easy to implement. However, it heavily relies on the accuracy and quality of the metadata. If the metadata is incomplete or inaccurate, the similarity search results may not be reliable.

| Advantages | Disadvantages |
|---|---|
| Simple and easy to implement. | Relies heavily on the quality of metadata. |
| Can be effective if the metadata is accurate and comprehensive. | Limited in capturing visual similarities between images. |
Perceptual hashes approach
Perceptual hash is a generic term that refers to a family of algorithms that generate hash values based on the visual content of an image. These algorithms typically analyze the visual features of an image, such as color, texture and shape, to generate a hash value. These hashes are optimized to change as little as possible for similar inputs, meaning that even the smallest change in an image will result in a small change in the hash. The similarity between images is determined by computing the Hamming Distance, which measures the minimum number of substitutions required to transform one hash into another (lower number of permutation means more likely to be similar).

By comparing the hashes using this distance metric, perceptual hashes can effectively identify visually similar images with minimal variations.
Among the various algorithms used for computing perceptual hash, pHash (Perceptual Hash) is one of the most well-known and widely used algorithms. It uses discrete cosine transform (DCT) and high-frequency content analysis to convert images into frequency domain representations and extract the most significant frequency components. It’s the algorithm used in one of our experiments:
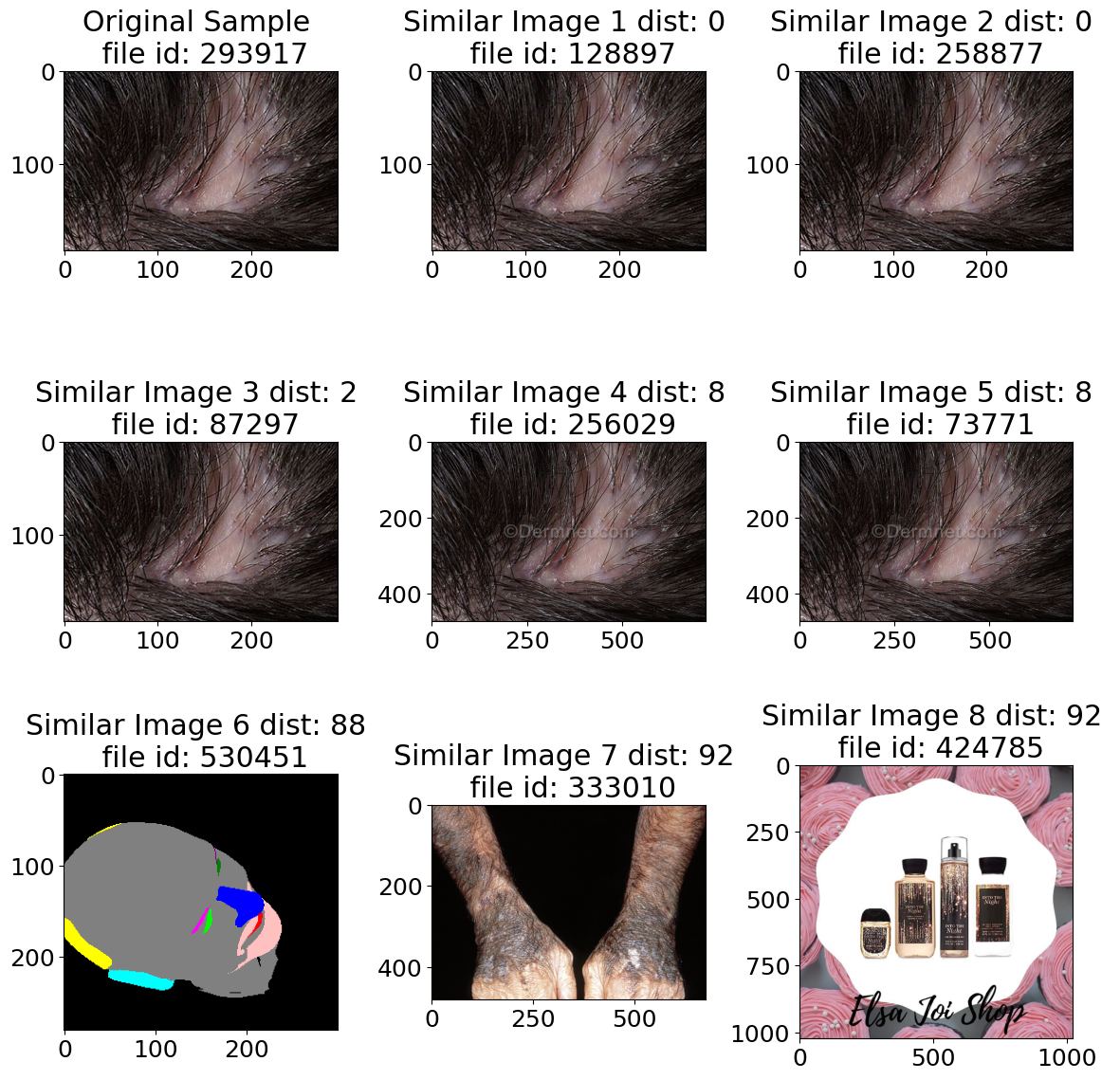
However, these algorithms might not capture more complex visual similarities since they focus on low level visual features (color, texture, shape).
| Advantages | Disadvantages |
|---|---|
| Robust against minor variations in images. | Limited in capturing complex visual similarities. |
| Efficient for large-scale image search. | May not perform well with images with significant variations. |
Other methods using the same approach:
- Average Hash
- Color Hash
Deep Learning approach
Deep learning models, such as convolutional neural networks (CNNs), can learn powerful image representations (embeddings) that capture high-level visual features. The learned embeddings or feature representations can be used to measure the similarity between images. One common approach is to compute the cosine similarity between the embeddings of two images. A higher cosine similarity score indicates a higher degree of similarity between the images.
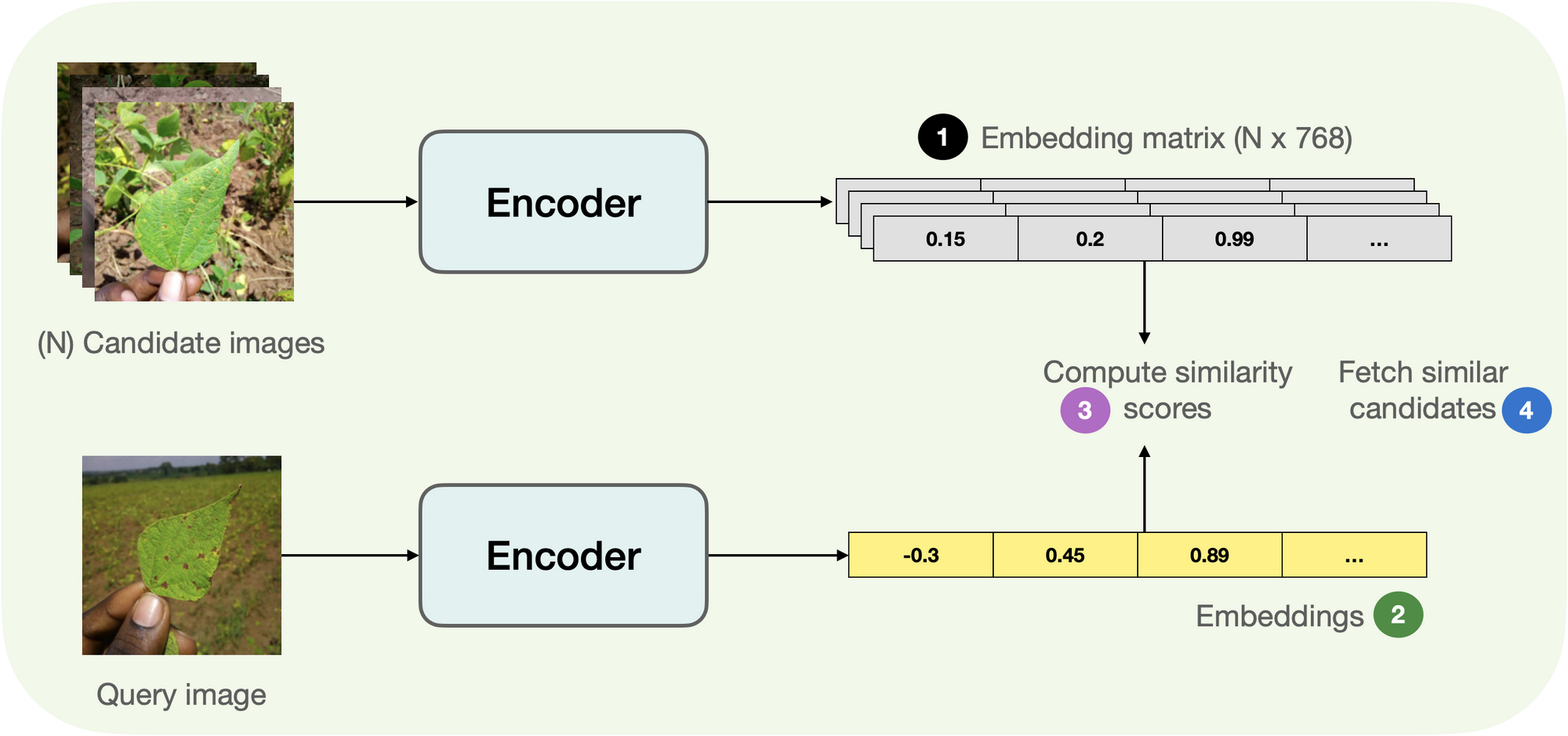
This approach can capture complex visual similarities and perform well on a wide range of image search tasks.
Using popular deep learning models trained on very large dataset (like ResNet or OpenAI's CLIP) to extract embeddings is one very good approach. These models have been trained on large-scale datasets and have learned to capture rich visual representations. The following image shows the results of our experiment to find similar images by using CLIP's embedding:

Even though the Deep Learning approach shows really good results, it's important to note that training deep learning models requires large amounts of data and significant computational resources.
| Advantages | Disadvantages |
|---|---|
| Captures complex visual similarities. | Requires large amounts of training data. |
| Can handle variations in images and different image domains. | Computationally expensive during training and inference. |
| Works for any data that can be fed into a neural network |
Other methods using the same approach:
- Siamese networks
- Triplet networks
Conclusion
In conclusion, image similarity search is a powerful technique with practical applications in Deep Learning. It enables us to find visually similar images, uncover patterns, remove duplicates, and build recommendation systems. The use of different techniques, such as metadata, perceptual hashes, and deep learning, offers flexibility based on specific requirements.
In future blog posts, we can delve into the implementation of image similarity search. We can explore the step-by-step process of using different techniques, provide code examples, and discuss best practices for optimizing performance. Stay tuned for our upcoming blog post on implementing image similarity search to unlock its full potential in your projects.
References
- https://huggingface.co/blog/image-similarity
- https://code.flickr.net/2017/03/07/introducing-similarity-search-at-flickr/
- https://medium.com/vector-database/the-journey-to-optimize-billion-scale-image-search-part-1-a270c519246d
- https://apiumhub.com/tech-blog-barcelona/introduction-perceptual-hashes-measuring-similarity/
- Babenko, A., Slesarev, A., Chigorin, A., & Lempitsky, V. (2014). Neural Codes for Image Retrieval. (ECCV)
- Gordo, A., Almazán, J., Revaud, J., & Larlus, D. (2016). Deep image retrieval: Learning global representations for image search. (ECCV)
- A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, I. Sutskever. Learning Transferable Visual Models From Natural Language Supervision. (2021)