
FeatUp: A Model-Agnostic Framework for Features at Any Resolution
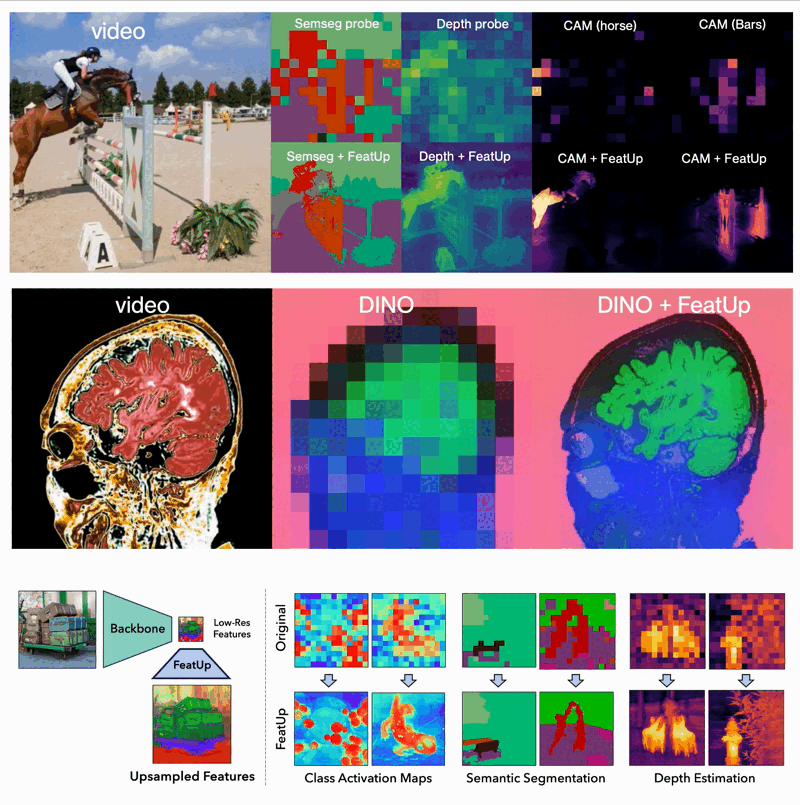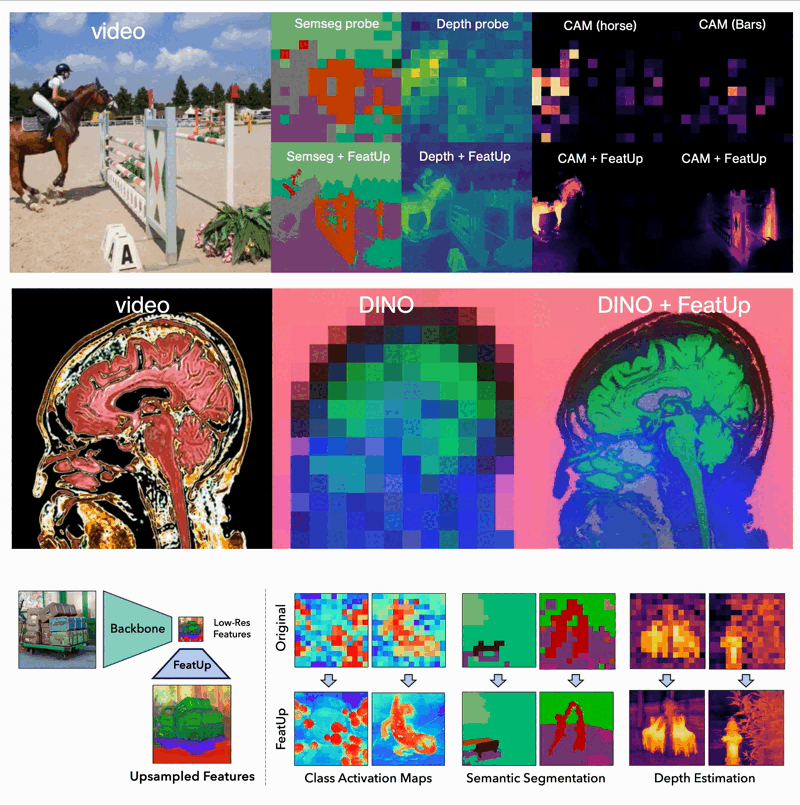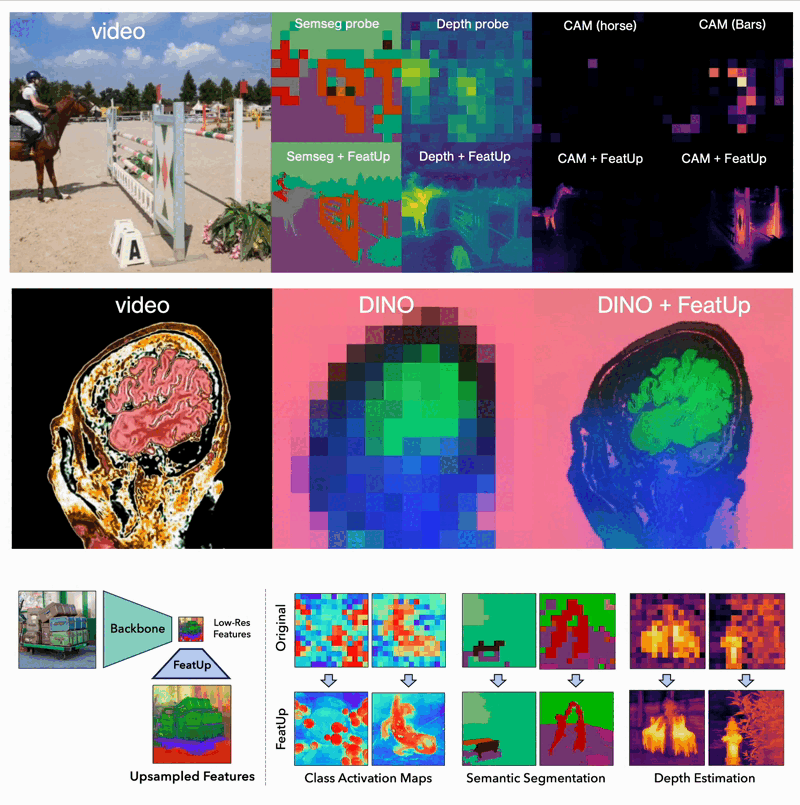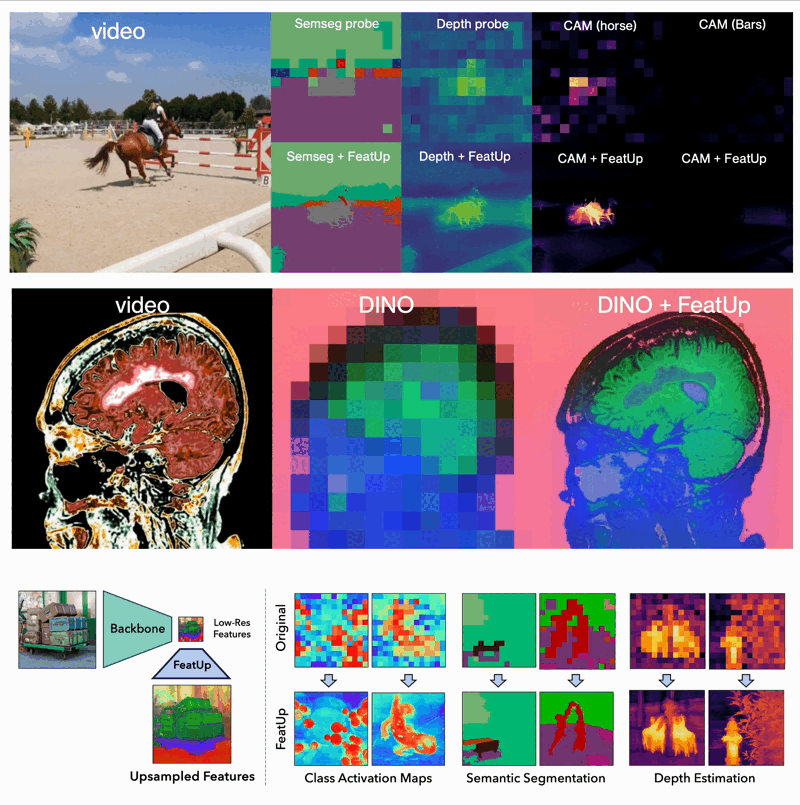
The world of computer vision is constantly pushing the boundaries of what machines can "see" and understand. A new framework called FeatUp takes a significant leap forward by enabling models to extract high-resolution features from images. This innovation draws inspiration from 3D scene reconstruction techniques, specifically Neural Radiance Fields (NeRF).
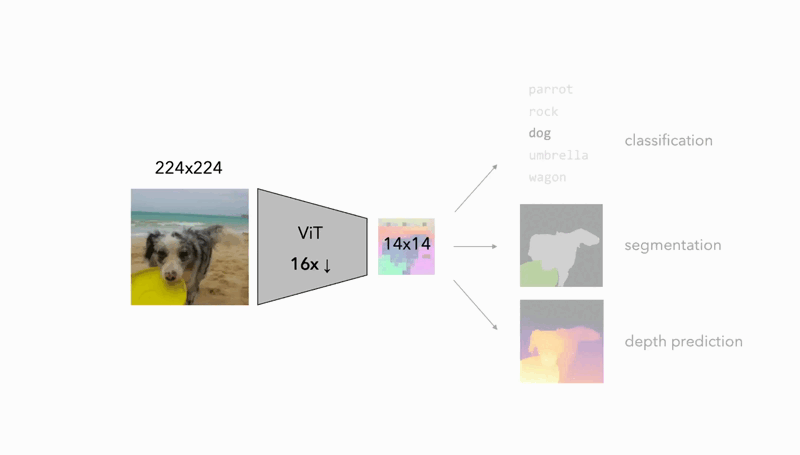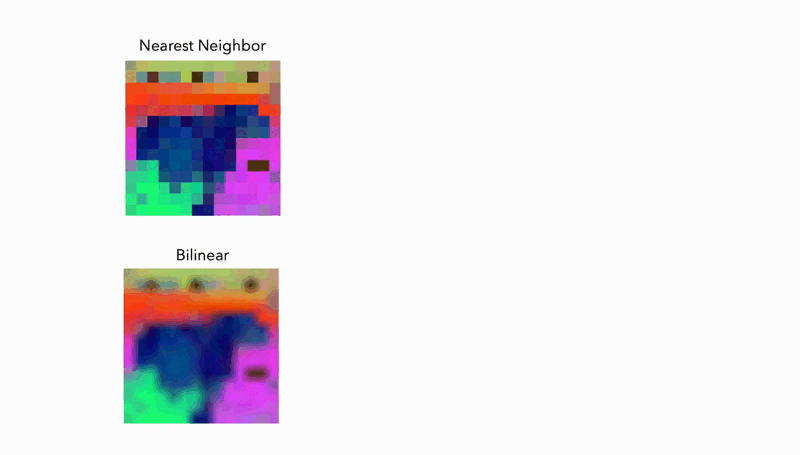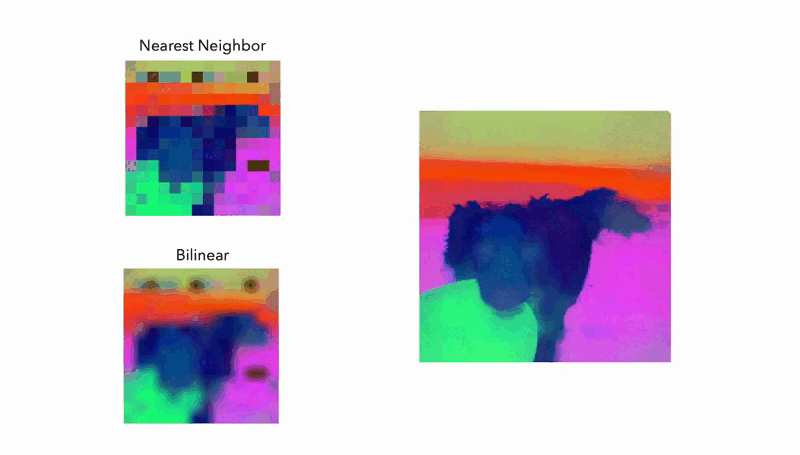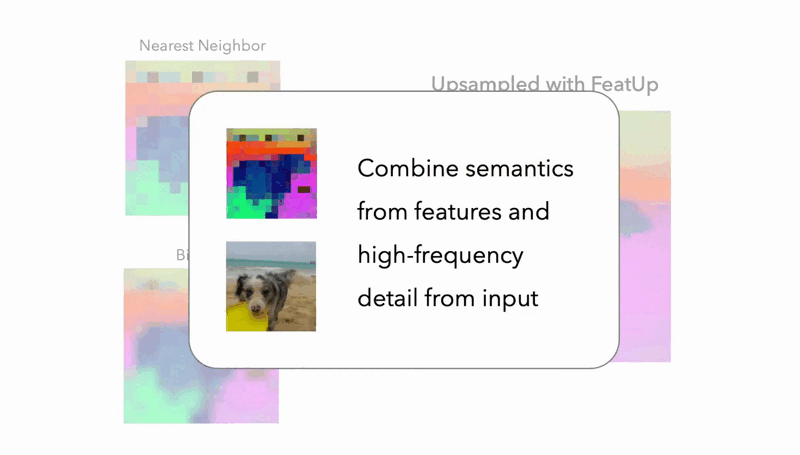
Multi-View Consistency
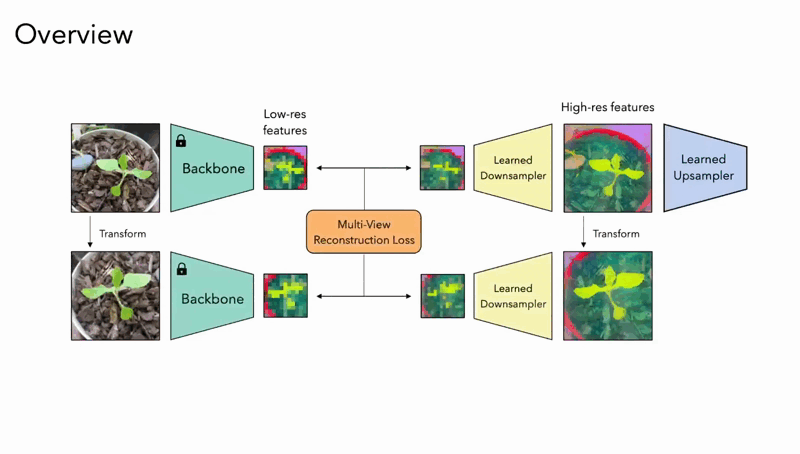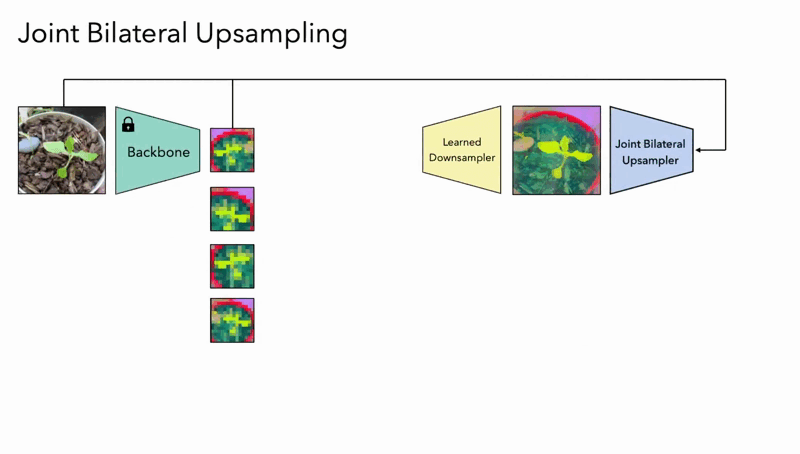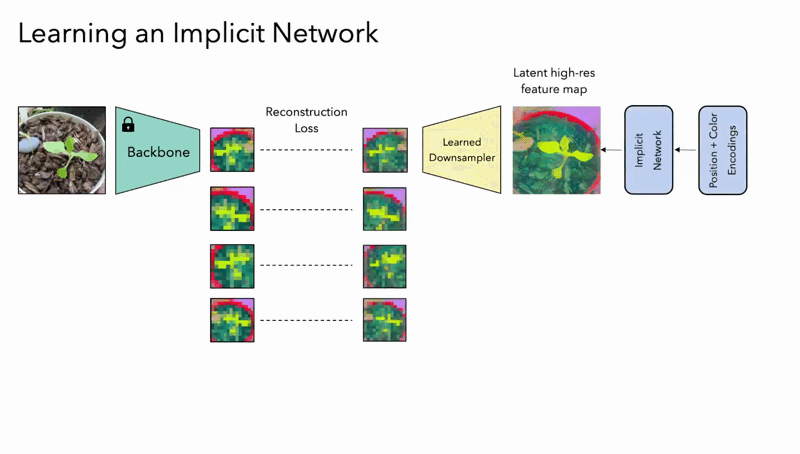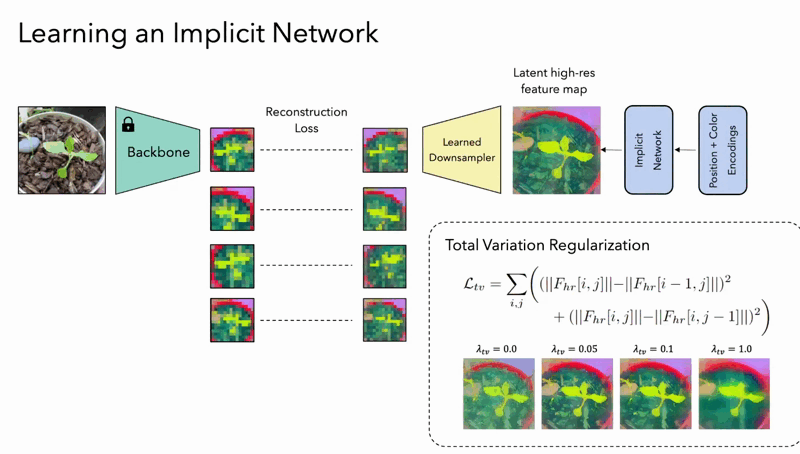
The magic behind FeatUp lies in its core principle: multi-view consistency. Imagine showing a picture to someone from different angles and distances. By analyzing these viewpoints, they can build a much richer understanding of the scene. FeatUp works similarly. It processes the same image from various augmentations (rotated, scaled, etc.) to grasp the underlying high-resolution details. This approach ensures that the extracted features retain their semantic meaning, allowing the model to form a deeper understanding of the spatial relationships within the image.
Two Upsampling Techniques for Different Needs
FeatUp offers two distinct upsampling techniques to cater to different scenarios:
- Guided Upsampling: This method aggregates insights from multiple low-resolution images of the same scene, altered slightly by transformations such as rotation or scaling. The model learns a generalized upsampling filter, enabling it to enhance resolution while adhering to detected semantic consistencies across the varied views.
- Implicit Model Upsampling: For tasks requiring exceptionally high detail from a single image, FeatUp can deploy an implicit model that fits directly to the unique features of that image. This approach closely resembles methods used in super-resolution, where specific characteristics of an individual image guide the learning process to achieve maximum resolution detail without losing semantic accuracy.
The guided upsampling method utilizes a Joint Bilateral Upsampling (JBU) filter, striking a balance between computational speed and the quality of resolution enhancement. The implicit model, on the other hand, allows for infinitely adjustable resolutions by simply fitting itself to a single image – a truly innovative feat.
FeatUp's Impact on Computer Vision Tasks
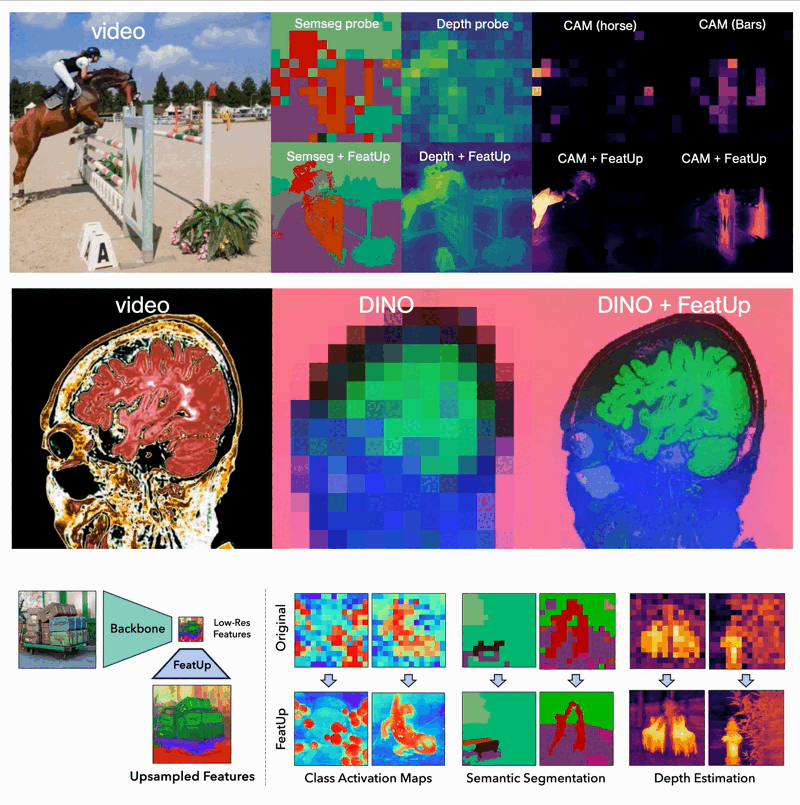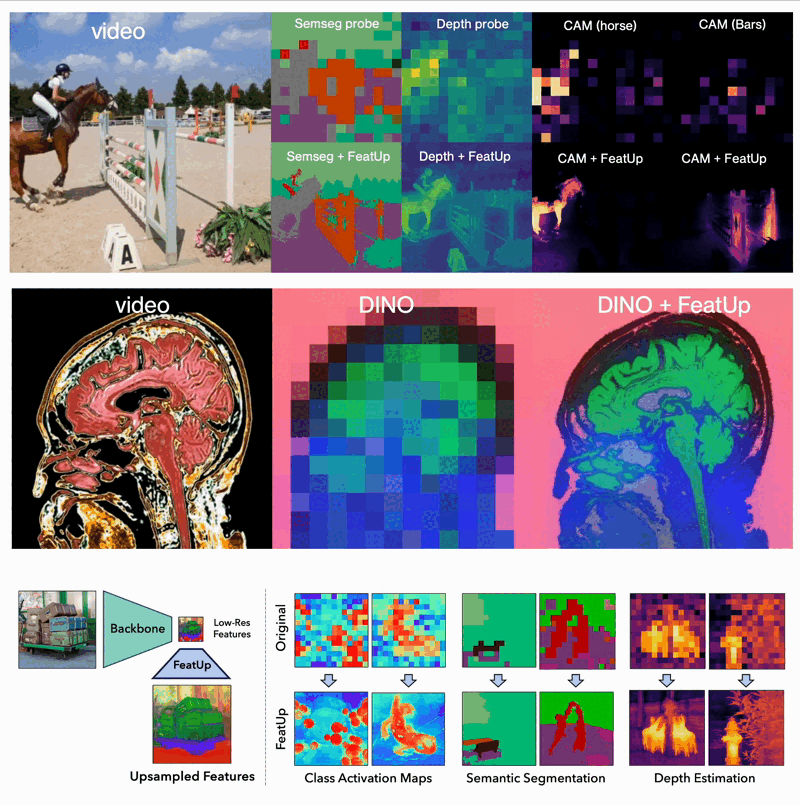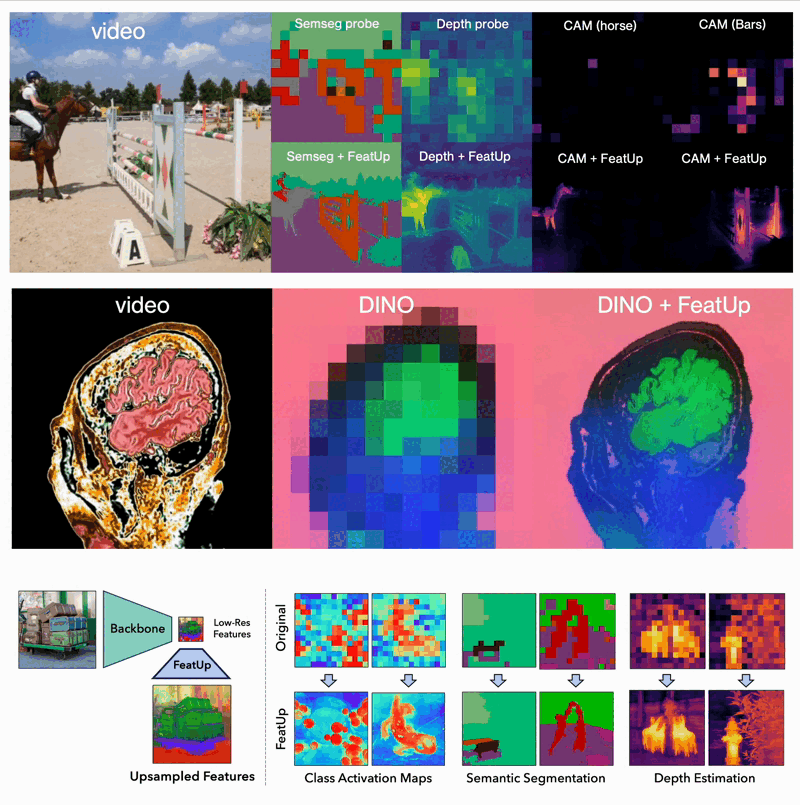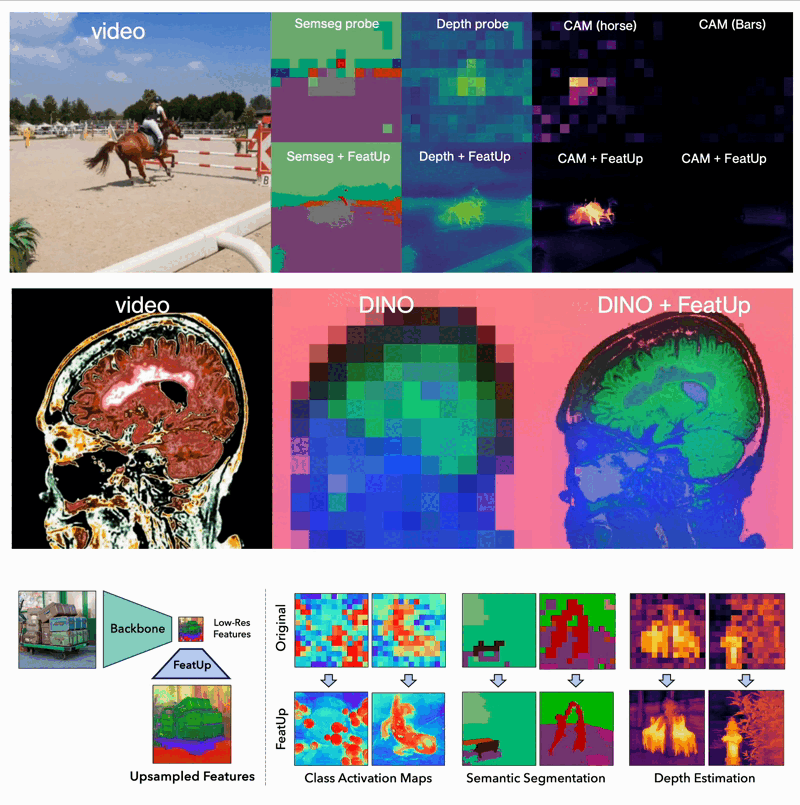
The implications of FeatUp are vast and transformative for various computer vision tasks:
- Dense Prediction Tasks: FeatUp improves performance on tasks like semantic segmentation and depth prediction by providing high-resolution features.
- Model Explainability: It enhances class activation map (CAM) generation, allowing for more detailed study of a model’s behavior.
- Transfer Learning: FeatUp features can be used as drop-in replacements for existing features, improving performance without re-training models.
- End-to-End Training: When integrated into training pipelines, FeatUp can improve the resolution and quality of features in end-to-end semantic segmentation.
Conclusion
FeatUp offers a robust, adaptable, and efficient way to elevate feature resolution while safeguarding their semantic integrity. Its model-agnostic nature allows seamless integration with existing architectures, unlocking immense potential for advancements in sectors that rely heavily on high-quality visual data processing. This framework not only empowers neural networks to handle intricate spatial details but also establishes a foundational methodology for further innovations in multi-view consistency and upsampling techniques within the realms of machine learning and artificial intelligence.
Paper: arxiv.org/pdf/2403.10516.pdf
Code: github.com/mhamilton723/FeatUp
Website: mhamilton.net/featup.html
As an event approaches, it is worth considering how details related to Genshin Impact cosplay costumes will affect the complete look. With practical wear in mind, reviewing details related to beginner costume choices also makes comfort and movement easier to judge. For choices related to details related to long cosplay wigs, men's cosplay costumes for anime fans can help narrow the options for a specific purpose. Before the preparation is complete, a balanced view of details related to photoshoot preparation can support both detail and comfort.
Member discussion