
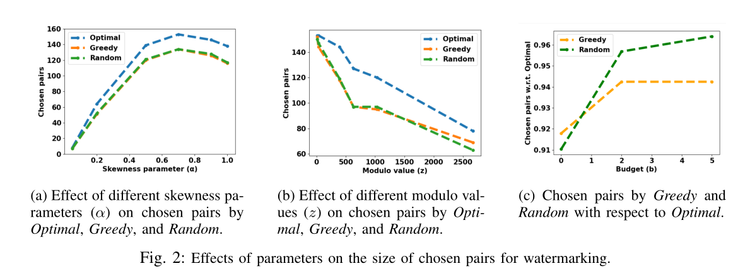
Hyper-VolTran

Hyper-Voltran is a tool built by Meta AI. Its main goal is to compute a 3D model from a single image input.
There already exist several similar tools, however Hyper-VolTran, through the use of a transformer module, allows a more consistent and realistic reconstructed model. In addition a HyperNetwork allows you to skip an optimization process generally used for other model generators. This allows a much faster running time as the model is constructed through one pass.
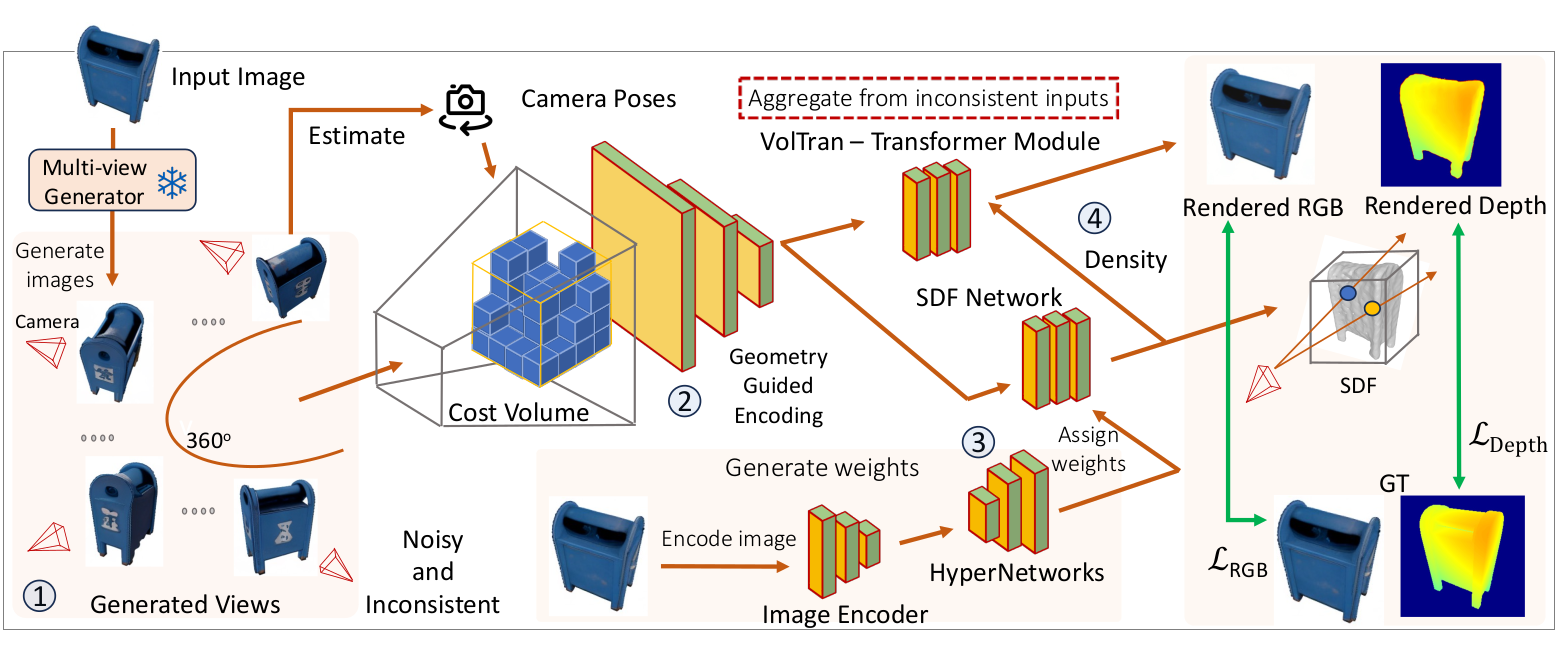
Genetating more views
From a single picture of an object a lot of information is intrinsically hidden. The first step is to generate more images. Hyper-VolTran uses an approach similar to Zero 1 to 3D (Zero123 [2, 4]), itself based on stable diffusion. The diffusion model is conditioned by the initial picture and camera information in order to infer new images. It creates new views of the object, with known camera parameters, the diffusion model invents the missing information.
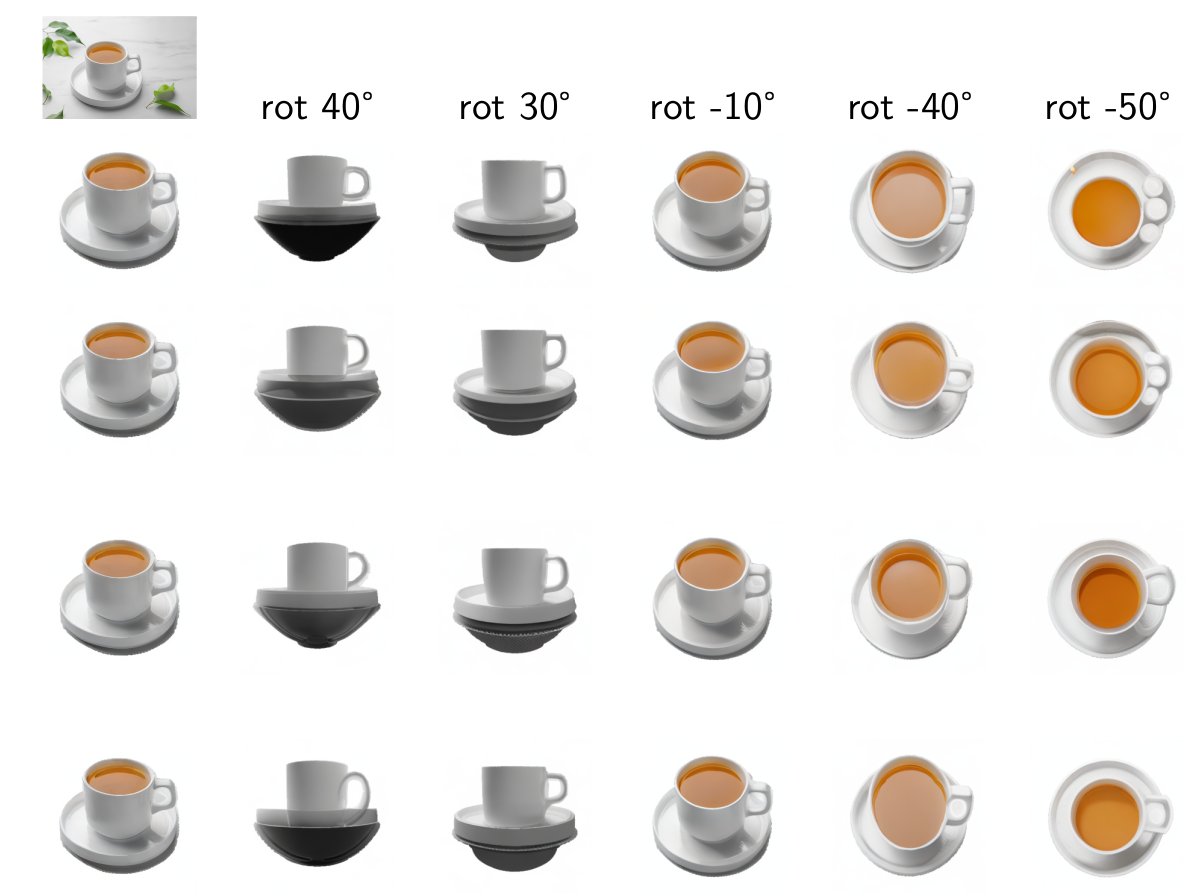
Zero123 has a relatively good understanding of 3D shape. As we can see above from rotation of 40° to a rotation of -50°, the total angle is 90° and it seems to correspond rather well from a horizontal view to a top view as should be expected. However the handle is not properly represented, moreover there is a strange guess of a bowl below the plate. Note that all those images are created from an online demo of Zero123 [5].

Volume generator
Hyper-VolTran creates virtual volumes on a grid (96x96x96) from the picture, grids which contain feature information about the model. This volume is constrained by projections on each image. Depth map and geometric features are computed for each image following the method of MVSNet [4].
Signed Distance Function
A Signed Distance Function (SDF) is a map associated to a 3D model. It gives, for each point of space, the distance to the border of the model (with negative sign if the point is within the model). From the SDF one can find back the model.
HyperNetwork
Part of Hyper-Voltran architecture is to give an (extended) SDF representing the model, from the initial picture. The SDF is not fully computed. Instead a HyperNetwork computes the weight of a Multi-layer Perceptron (MLP), which itself allows the computation of the SDF at any point of space for each color.
Transformer
Different views of the object, being generated by a diffusion model, are inconsistent. Any invented part has no reason to correspond between various pictures. Moreover the geometric interpretation of the pictures might differ even further as the interpretation is always tricky. Of course it might also be incompatible with the SDF previously generated. This might cause some issues when trying to merge all the data.
To solve those issues, Hyper-Voltran fuses the geometric data with the SDF using a transformer architecture. It allows to create a final MLP encoding the SDF and the density of each of the colors in space. This final MLP allows you to compute any view of the model using the spherical ray tracing technique. In addition the depth map can be computed from various views and a full model with its colors can be reconstructed.
Examples
Hyper-VolTran is not yet available for public use, however there are examples in the original publication [3]. A rather similar network One-2-3-45 [1], although simpler is available online for testing purposes One2345 [6].

References
- Minghua Liu, Chao Xu, Haian Jin, Linghao Chen, Mukund Varma T, Zexiang Xu, and Hao Su, One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimization, arXiv:2306.16928, 2023, p. 19. arXiv
- Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick, Zero-1-to-3: Zero-shot one image to 3d object, In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9298-9309, 2023. arXiv
- Christian Simon, Sen He, Juan-Manuel Perez-Rua, Mengmeng Xu, Amine Benhalloum, and Tao Xiang, Hyper-VolTran: Fast and Generalizable One-Shot Image to 3D Object Structure via HyperNetworks, arXiv:2312.16218, 2023, p. 10. arXiv
- Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan, Mvsnet: Depth inference for unstructured multi-view stereo, European Conference on Computer Vision (ECCV), pp. 767-783, 2018. arXiv
- Zero123 demo
- One2345 demo


Member discussion