
Interpretable Medical Image Diagnosis with Explicd
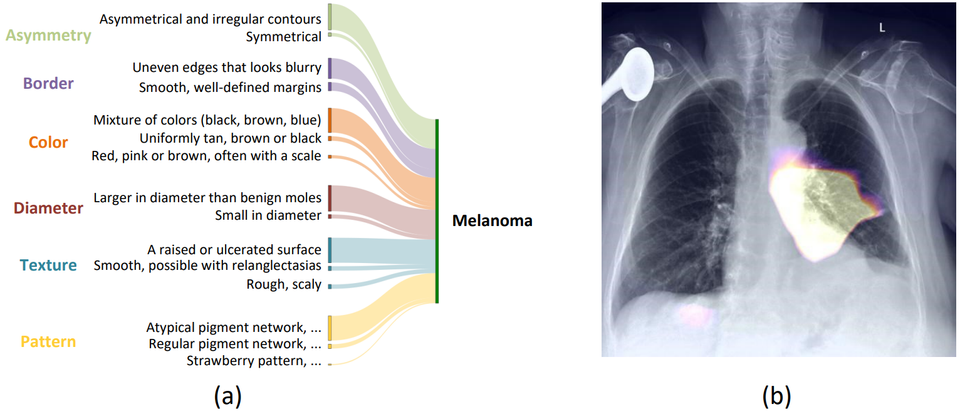
As deep learning continues to revolutionize medical imaging, one critical question keeps surfacing: how can we trust what the model sees ? Despite achieving high accuracy in tasks like skin cancer classification or chest X-ray analysis, most models remain black boxes. For real-world clinical adoption, interpretability is essential.
This is the challenge tackled by Explicd, a model introduced by Gao et al. at MICCAI 2023. The authors propose a novel approach to bridge the gap between AI predictions and clinical reasoning, by aligning learnable visual features with human-understandable concepts.
🧠 From Pixels to Concepts
Instead of post-hoc methods like Grad-CAM [2], Explicd bakes interpretability into the model itself. It learns to associate visual concept tokens directly with textual clinical knowledge. For instance, imagine you are classifying a mammogram. A radiologist might describe a suspicious mass as having an "irregular margin" or "spiculated border." These are concrete visual patterns that experts use every day. Explicd is designed to learn those patterns, align them with their natural language descriptions, and use them to both classify the image and explain its reasoning. It is worth noting that this process requires no manual annotation of visual concepts in the training data. It only requires to use clinicians guidelines or LLM-generated descriptions for each class.

🏗️ Architecture Breakdown
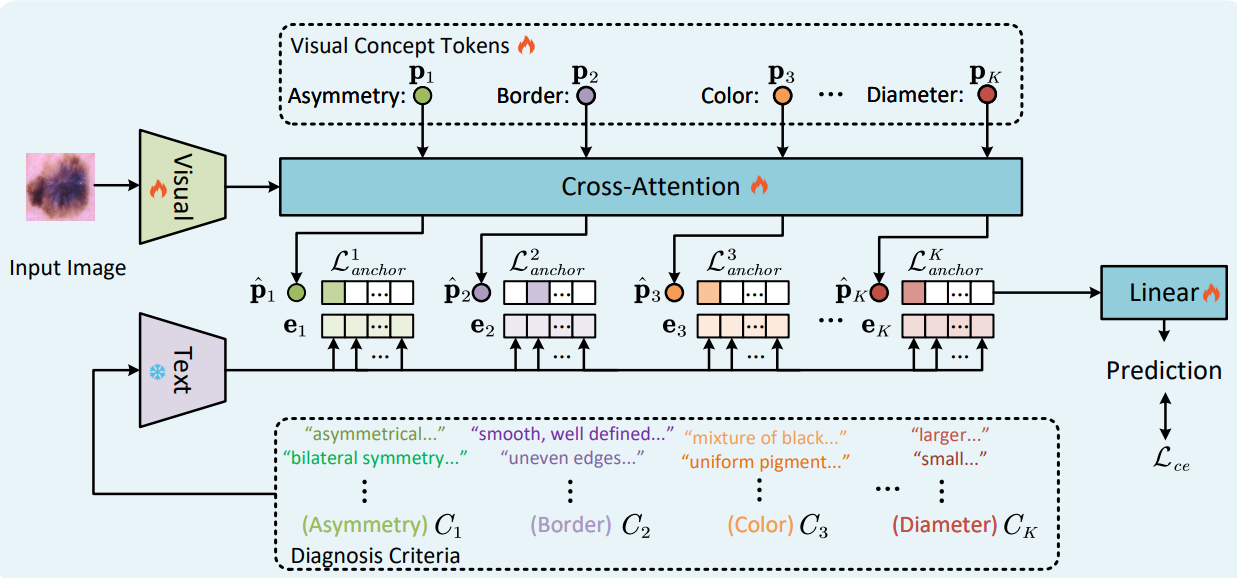
Explicd is built on a Vision Transformer (ViT), but with several key additions:
1. Visual Concept Tokens
- Learnable embeddings that attend to different parts of the image.
- Meant to represent distinct semantic features (e.g., border, texture, density).
2. Textual Concept Embeddings
- Natural language descriptions of visual features (e.g., “homogeneous texture”).
- Encoded using a text model like BERT or CLIP.
- Serve as “knowledge anchors".
3. Shared Embedding Space
- Both image and text concepts are projected into a common space.
- The model uses contrastive learning to align visual and text tokens.
During training, Explicd uses a multi-task objective:
- Classification loss: For standard image label prediction (e.g., benign vs malignant).
- Concept alignment loss: A contrastive loss that aligns each visual concept token with its corresponding text description.
📊 Performance of Explicd
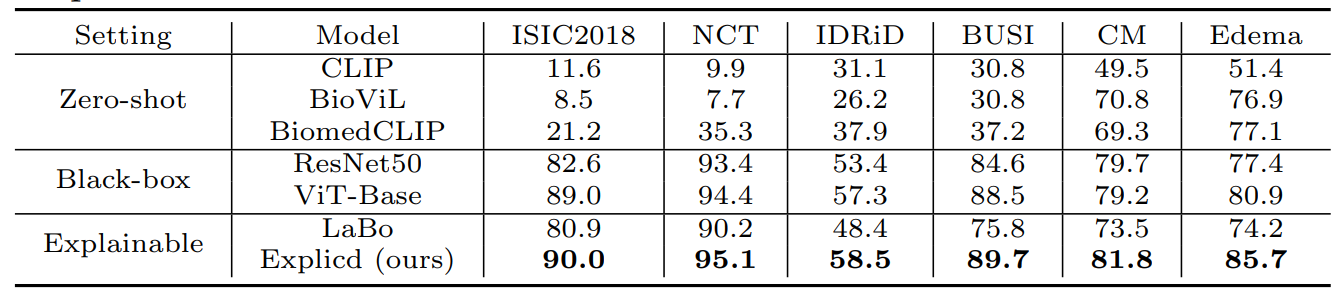
To demonstrate the performance of their frameworks, the authors compared different architectures across five diverse medical imaging classification tasks, covering a range of modalities and clinical challenges. These include mammography, chest X-ray, skin lesion images, and histopathology. The classification problems vary in complexity, from binary tasks (e.g., malignant vs. benign) to multi-class settings with up to seven categories, ensuring a comprehensive evaluation across both low- and high-level visual variability.
🔍 Output interpretability
At inference time, Explicd doesn’t just predict a class — it also tells you which visual concepts were most relevant and how strongly they contributed via the Concept Alignment Score (CAS). For example, in a malignant tumor case, the model might output:
- Irregular margin – 0.89
- Spiculated appearance – 0.83
- High contrast region – 0.77
These are semantic explanations, aligned with the language clinicians use in diagnosis. Instead of post-hoc heatmaps or opaque embeddings, Explicd gives you a transparent rationale rooted in domain knowledge.
🛠️ Conclusion and future work
Explicd is more than a model, it is a framework for aligning AI decisions with human knowledge. That’s not just useful for debugging or visualization. It points us in the right direction: toward systems that don’t just see, but that can provide insights in our language. However, no model is perfect. Explicd’s interpretability depends heavily on:
- The quality and specificity of the concept descriptions
- The semantic richness of the textual encoder
Future directions might include:
- Unsupervised concept modeling
- Extending to multimodal inputs (e.g, 3D scans, videos)
🌰 Explicd in a nutshell
- Explicd: An explainable ViT model for medical imaging
- Aligns visual features with text-based clinical concepts
- Outputs concept-based explanations with confidence scores
- Trains via contrastive + classification losses
- Enables interpretable, trustworthy predictions
References :
[1] Aligning Human Knowledge with Visual Concepts Towards Explainable Medical Image Classification. Gao et al. MICCAI 2023. https://arxiv.org/pdf/2406.05596
[2] Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. Selvaraju et al. IJCV 2019. https://arxiv.org/abs/1610.02391
[3] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. Dosovitskiy et al. ICLR 2021. https://arxiv.org/abs/2010.11929