
MultiFacetEval
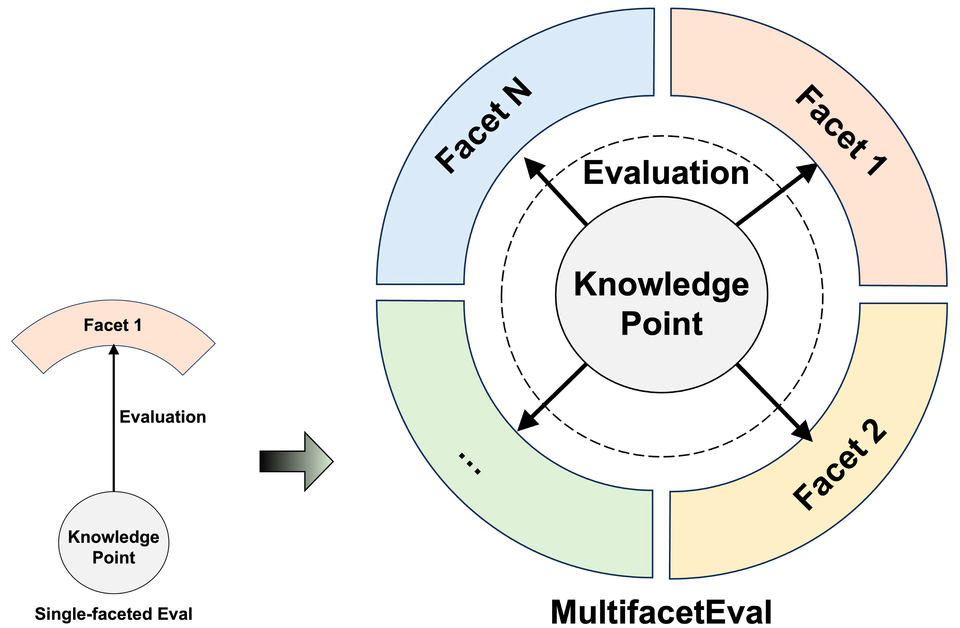
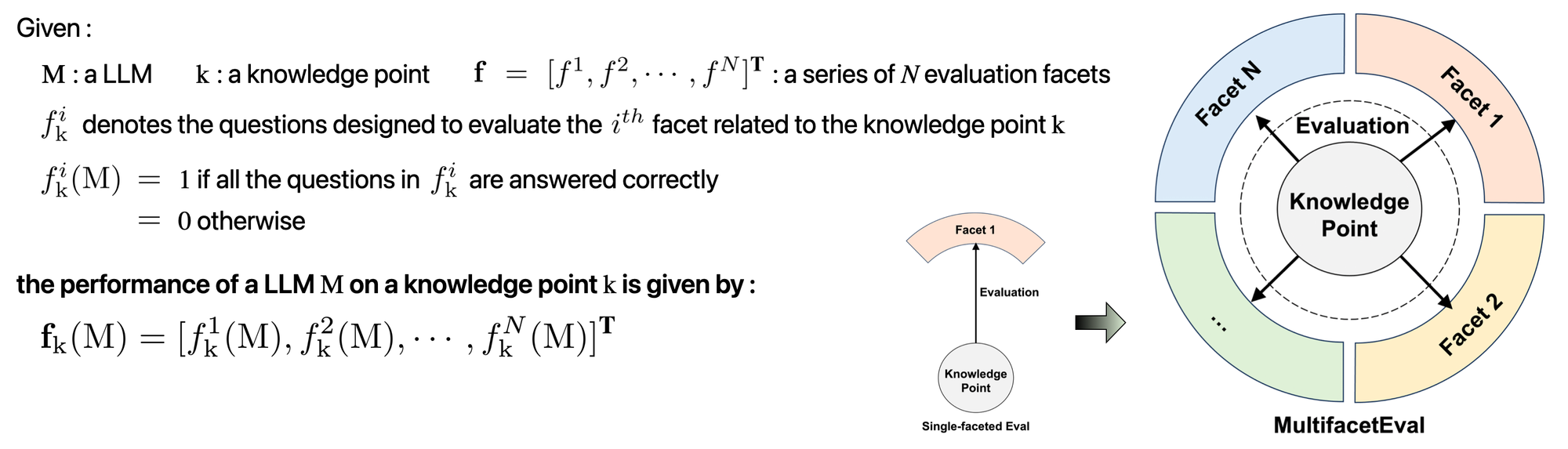
Multifaceted Evaluation to probe LLMs in mastering medical knowledge
Yuxuan Zhou et al., June 2024
Large language models (LLMs) have achieved impressive results in medical evaluation benchmarks like MedQA. Despite this, there remains a significant gap between their reported performance and their practical effectiveness in real-world medical scenarios. In this blogpost, we study the reasons using a comprehensive examination schema to assess the true mastery of medical knowledge by LLMs.
The gap between evaluation results and practical performance
Famous general LLMs (e.g. GPT, Gemini) and medical-domain-specific LLMs have encoded vast medical knowledge through pre-training and fine-tuning on massive amounts of data. The recent LLMs like GPT-4 and Med-Palm 2 have demonstrated significant performance on several medical benchmarks and outperformed the previous SOTA by a big margin.
But despite the impressive performance, LLMs struggle with real-world medical problems, according to several papers including [1] and [2]. Thus, the objective of the paper is to study the causes of this gap by systematically investigating the depth of knowledge mastery in LLMs.
Most current medical benchmarks evaluate LLMs through medical question-answering tasks with problems collected from medical exams, scientific literature and consumer health questions. Others assess LLMs using medical dialogues or NLP tasks based on medical texts. However, these benchmarks typically rely on a single facet i.e. a specific question type (e.g. multiple-choice questions), which can lead to overestimating the performance of LLMs, especially if the models have been fine-tuned for those question types. Some benchmarks have attempted to evaluate LLMs' capabilities across different facets, but they've used separate sets of knowledge points for each facet. Thus, these benchmarks don't accurately reflect LLMs' mastery of the same knowledge points across various facets.
Here's an example to illustrate the issue with GPT-3.5-turbo responding to two medical exam problems :
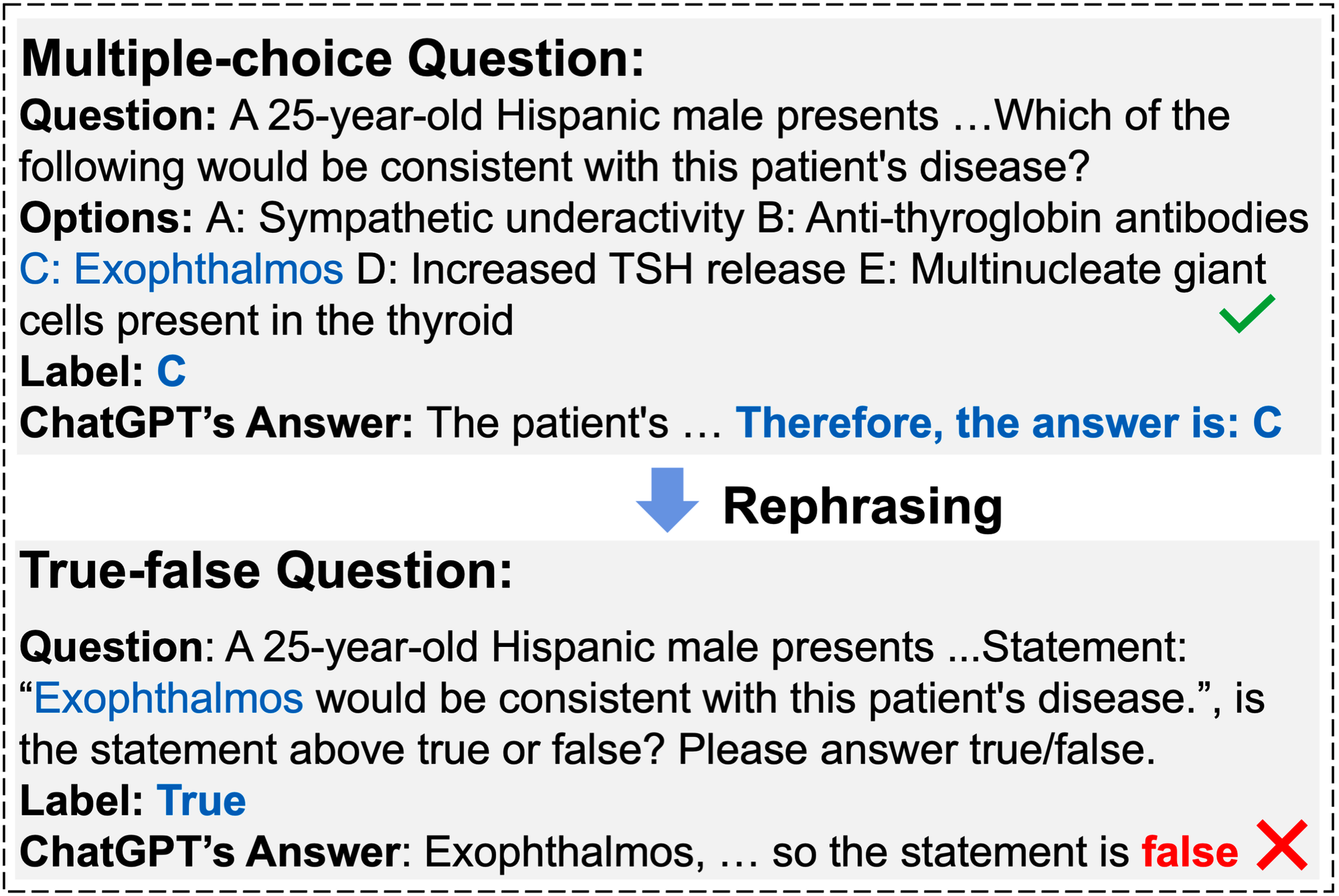
MultiFacetEval
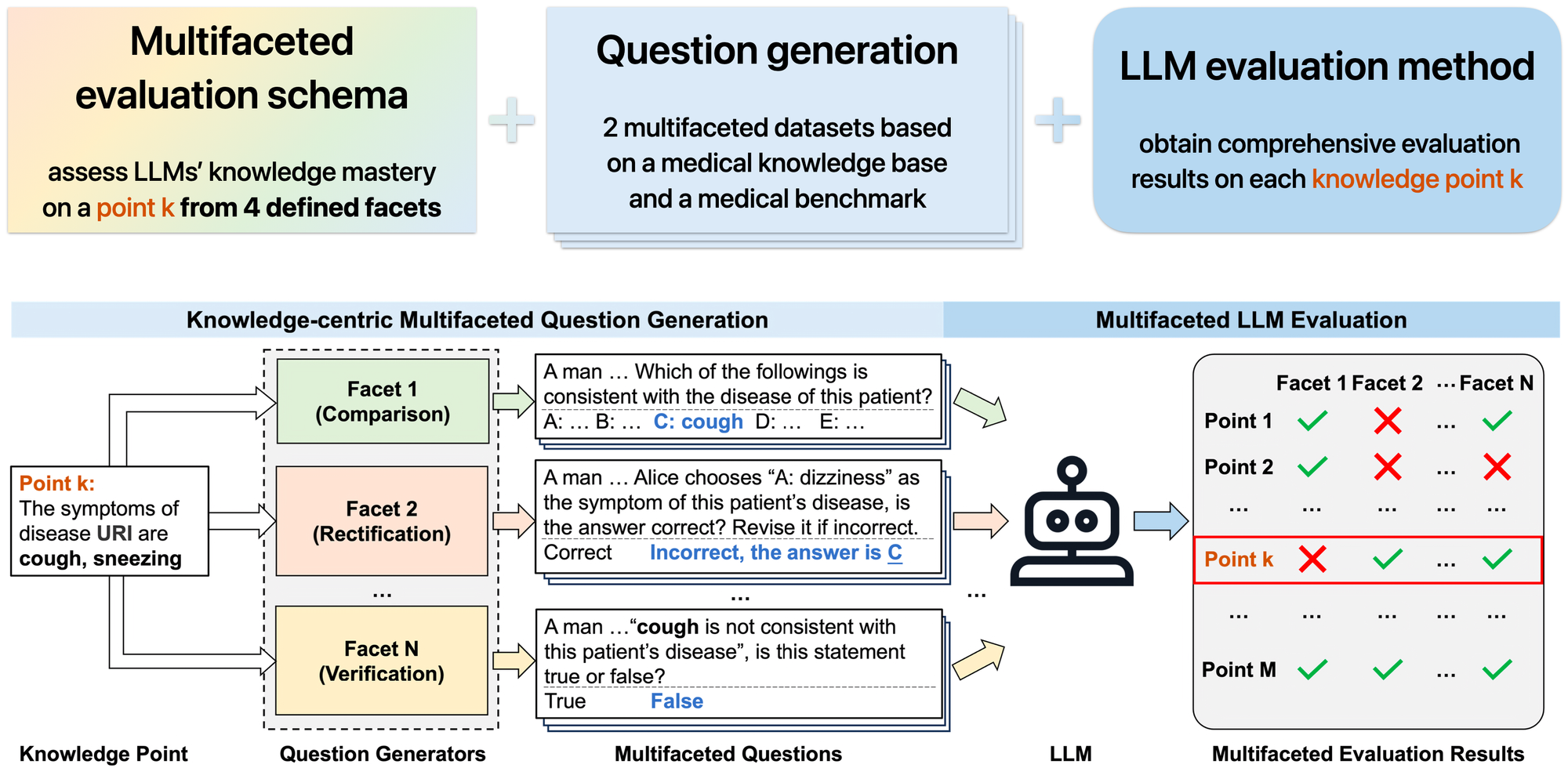
Multifaceted evaluation schema
This schema is inspired by modern education systems; they typically use various assessment methods, such as assignments, projects and exams, to evaluate whether the students have mastered a knowledge point. The goal is to provide more comprehensive information about the mastery of a specific knowledge point
Considering the characteristics of medical scenarios, the paper defines 4 evaluation facets of capabilities that are crucial for addressing real-world medical problems, and as many associated question types :
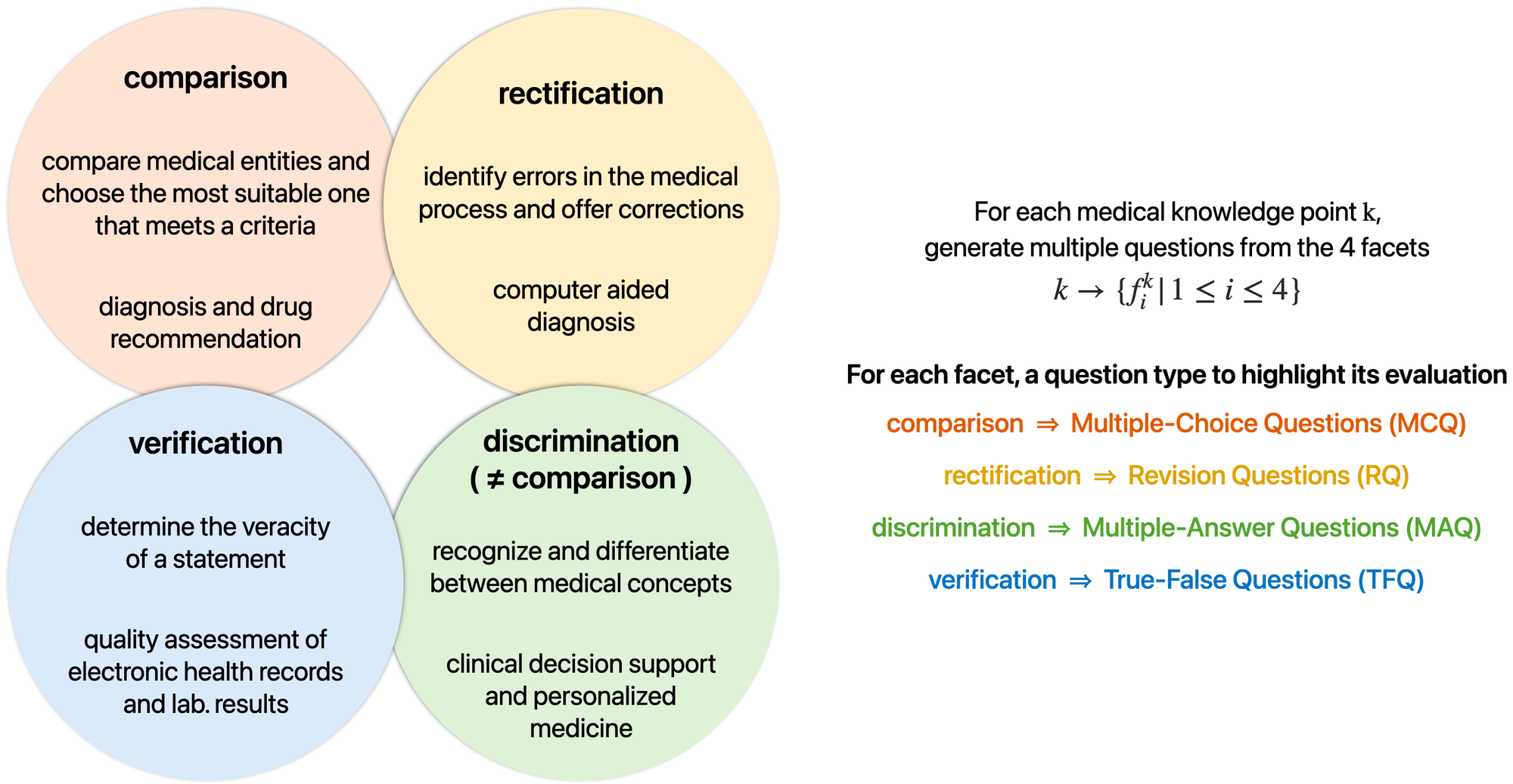
Questions generation
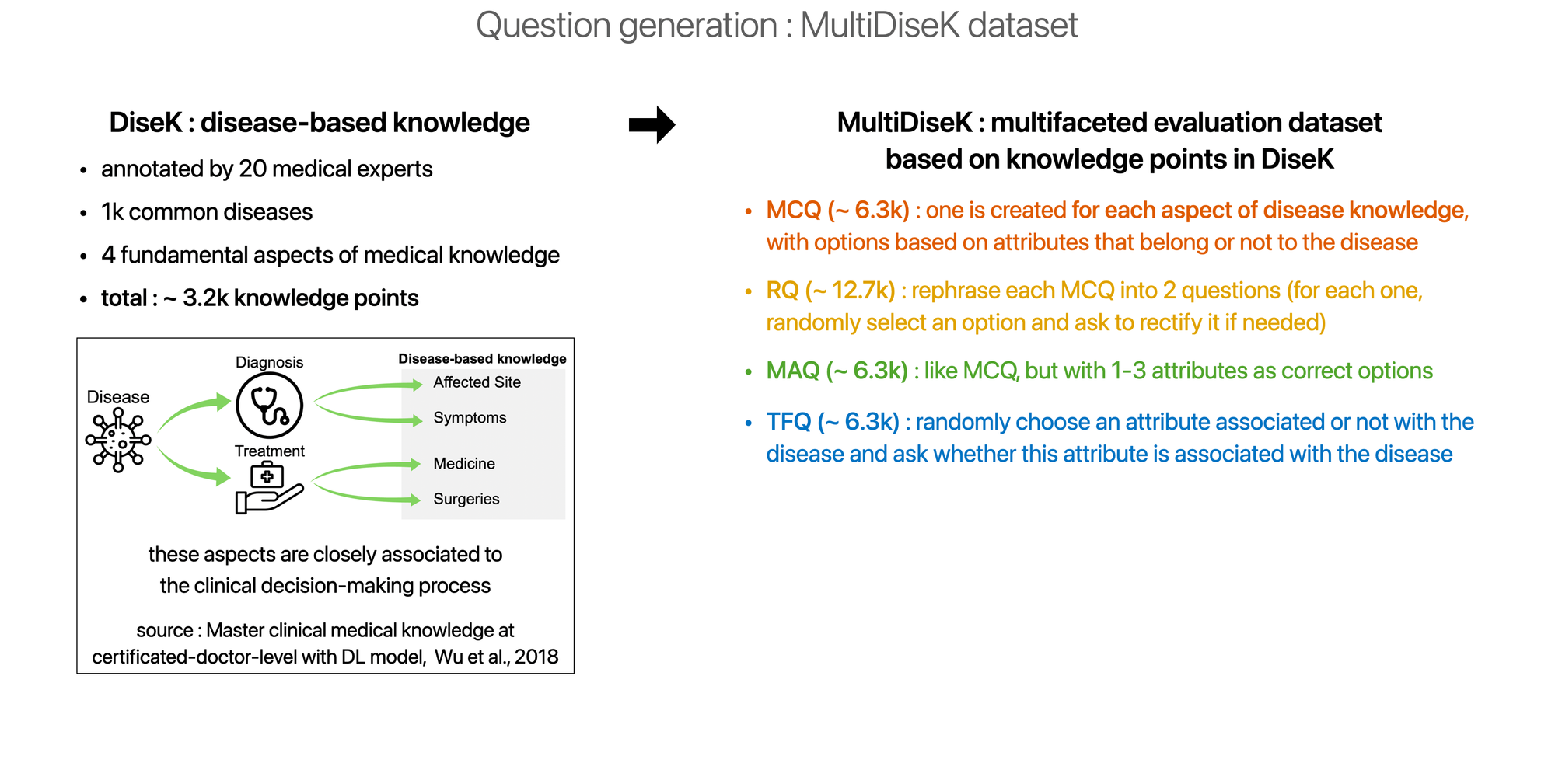
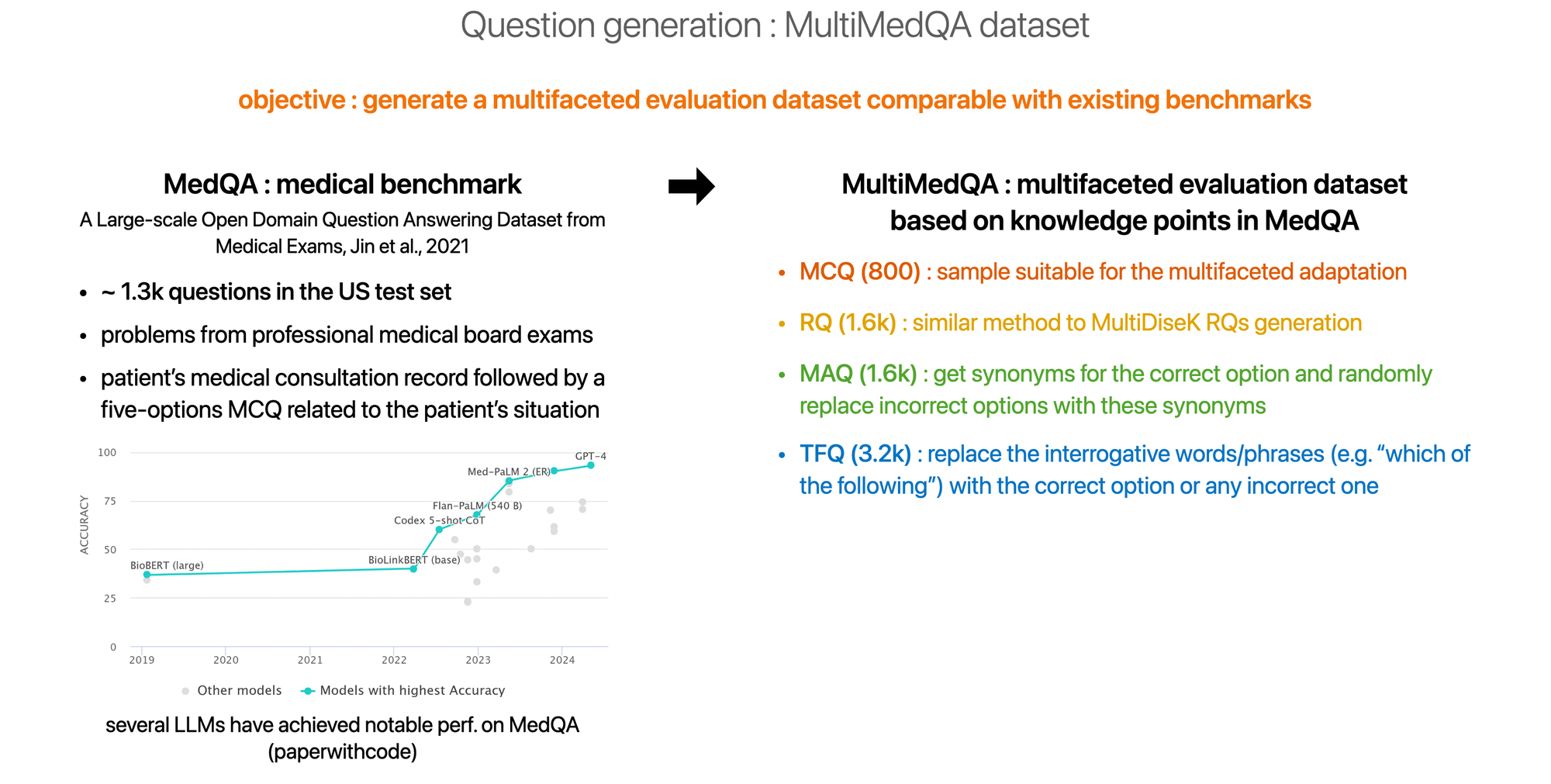
Please click on a image to enlarge it.
Multifaceted LLM evaluation

Experimental results
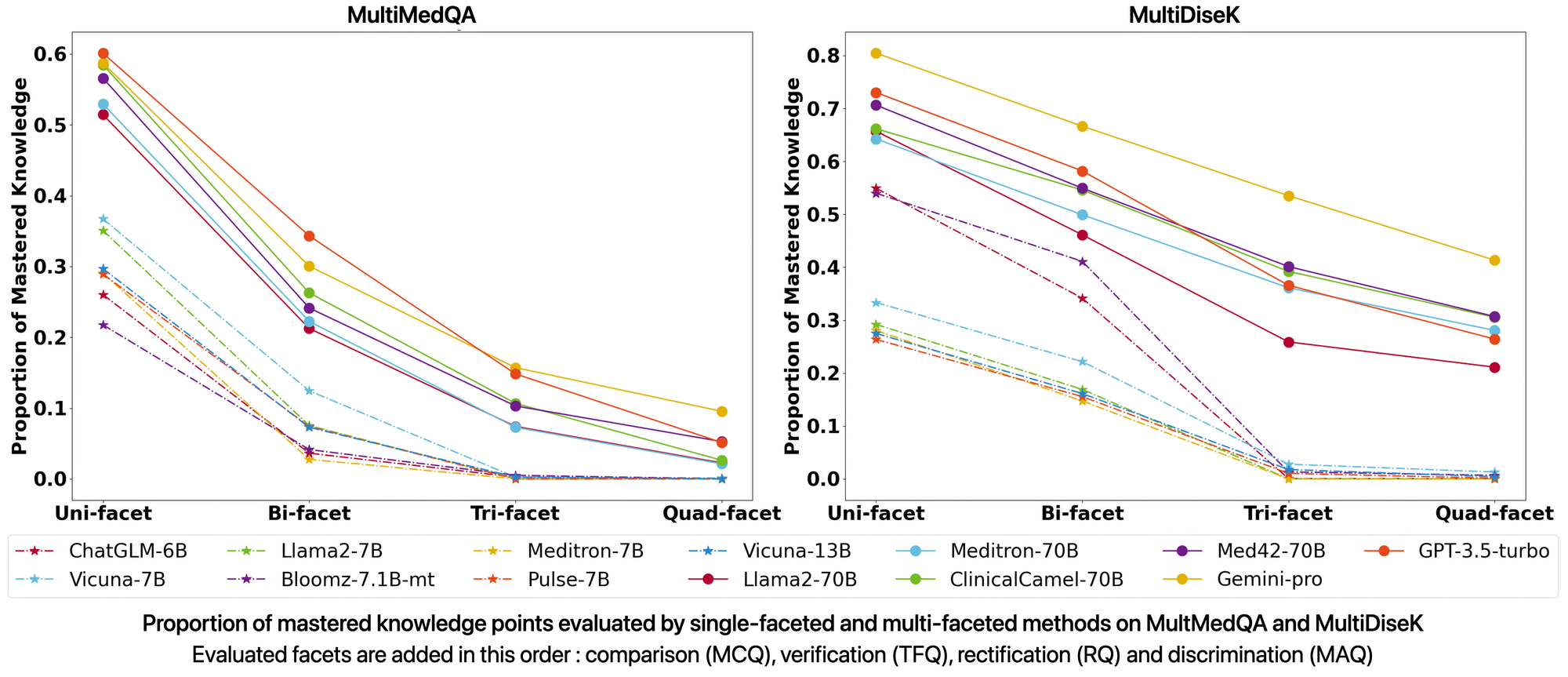
Some observations :
- LLMs above 70B have mastered a significant number of knowledge points when evaluated from the comparison facet
- as the number of evaluated facets increases, the proportion of mastered knowledge points in various LLMs sharply decreases 📉
- smaller LLMs performance approaches zero when evaluated by ≥ 3 facets 👌
- same conclusions with different sequences of evaluation facets
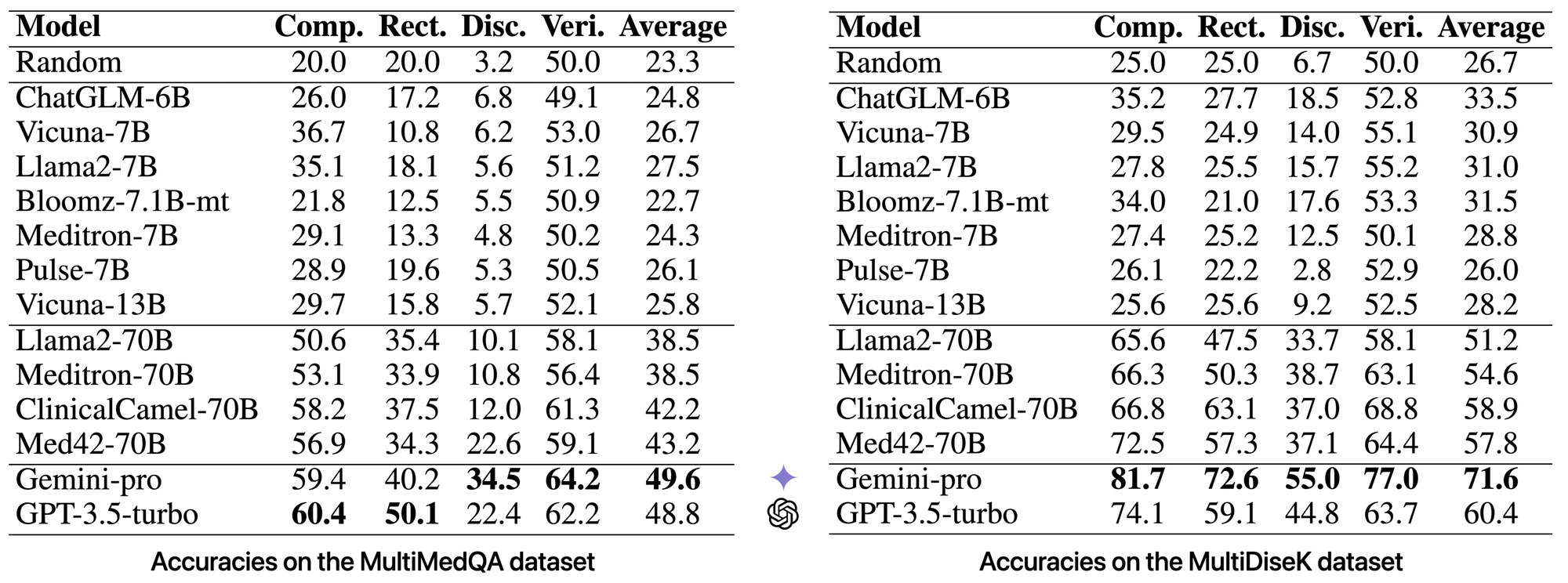
Some observations :
- LLMs generally perform better on MultiDiseK since the questions don’t require analysis of specific medical cases
- Gemini-pro achieves the highest performance on both datasets
- Several medical LLMs (Med42, ClinicalCamel) significantly outperform their base model (LLama2-70B)
- LLMs ≤ 13B perform only slightly better than random guessing 🎲
The experimental results on these two generated datasets show that LLMs' true mastery of medical knowledge is significantly lower than their reported performance on the current benchmarks. This indicates that LLMs actually lack the depth, precision, and comprehensiveness required for real-world medical applications and suggests they aren't ready (yet) for practical use in medical tasks.
References
- [1] LLM in medicine, Thirunavukarasu et al., 2023
- [2] The shaky foundations of LLMs and FMs for electronic health records, Wornow et al., 2023
- MultiFacetEval : paper, code+datasets
- MedQA : code+datasets, benchmarks
- Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine (Nori et al., 2023)