
Overview of Self Supervised Learning

Introduction
In this blog post, we’ll explore the concept of self-supervised learning, its potential for pushing AI toward human-level intelligence, and how it can help us sidestep the bottleneck of supervised learning.
Context
The explosive growth of AI in recent years has been primarily driven by supervised learning, a paradigm in which models learn from large amounts of carefully labeled data. While effective, supervised learning has its limitations – most notably, the inability to train generalist models that can perform multiple tasks and continue learning without massive amounts of labeled data.
If we were to illustrate this problem, we could ask you this question :
- How can a teenager learn to drive a car in around 100 hours while autonomous driving car still can’t fully drive with thousands of hours of training ?
- How can a child learn to recognize dogs from a few images or drawings while some SOTA model can still confuse dogs and muffin while trained on millions of images ?

Why
One hypothesis is that human have is common sense. The concept of common sense is something that humans take for granted - we simply assume that we possess a base level of knowledge that encompasses a wide array of topics. But when it comes to artificial intelligence, the idea of common sense becomes much more complicated.
Common sense can be thought of as a broad set of generalized knowledge about the world that forms the backbone of biological intelligence. It includes things like our understanding of cause and effect, our ability to interpret language and visual cues, and our ability to reason about the world around us.
Despite years of research and development, the challenge of imbuing AI systems with common sense remains a significant obstacle. Those in the industry often refer to common sense as the "dark matter" of AI, in reference to the mysterious, unobservable substance that is thought to make up most of the universe's mass.
While progress has been made in certain areas, like language processing and image recognition, the ability to imbue machines with true common sense remains elusive. Researchers like Yann LeCun of FAIR are among those working to solve this puzzle, but it's clear that there is still much work to be done before we can enjoy the benefits of truly intelligent AI systems.
Supervised Learning is not enough
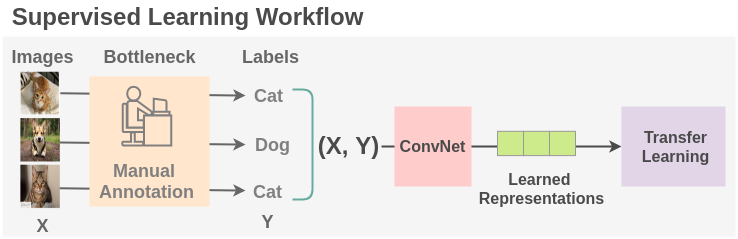
When it comes to training AI models, supervised learning has long been the gold standard. By providing large amounts of labeled data, this technique is able to train specialist models that excel in specific tasks - from image recognition to natural language processing.
However, relying solely on supervised learning has become a bottleneck in AI development. It all comes down to the data: supervised learning requires a large amount of annotated data, which can be both expensive and time-consuming to produce. Furthermore, not every task has enough data available to train a specialist model. This is particularly true for low-resource languages and other niche applications.
While transfer learning allows for the transfer of models trained on a common dataset to other tasks, this approach is still limited by the size and labeling of the original dataset. For instance, ImageNet1K - one of the largest image datasets available - comprises only 1.2 million images across 1,000 classes.
Compared to this, self-supervised learning models offer a much more promising solution. With datasets like LAION boasting more than 400 million images that lead to the training of CLIP, and DinoV2 trained on a staggering 1.2 billion images, these models offer the potential for significantly more comprehensive training data and more accurate models. This raises the question - is the supervised learning approach still the best we can do?
That’s where self-supervised learning comes in. Inspired by how humans learn through observation and building hypotheses about the world around them, self-supervised learning gives AI systems a deeper understanding of real-world scenarios beyond what’s specified in the training data set.

Self-supervised Learning
What is SSL ?
The goal of self-supervised learning is to enable the model to learn the intrinsic structure of the data without relying on human-annotated labels. This includes techniques such as pretext tasks and contrastive learning.

The idea is to create meaningful and generic representations that can be used for a wide range of downstream tasks. These models are trained on tasks where the labels are generated from the data itself. This approach means that the cost of these labels is almost zero in terms of time, money, and error. This eliminates the need for human labeling, allowing for the use of much larger datasets than would be feasible with supervised learning alone.
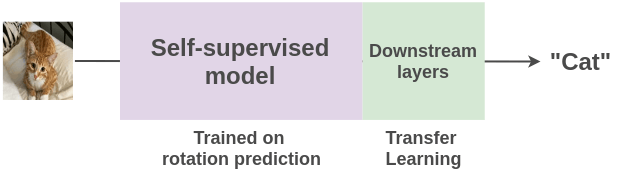
Once a self-supervised learning model has been pretrained, it can be applied to a variety of tasks, including zero-shot classification, feature extraction, and downstream tasks like image or language classification. This allows for much more flexible and adaptable AI models, capable of learning from and applying knowledge to new, varied contexts.
Self-supervised learning represents an exciting new frontier in AI development, with exciting potential for problem-solving and innovation.
Already in use in NLP

While the popularity pf self-supervised learning is a relatively recent in the world Computer Vision, it's not an entirely novel approach. In fact, the technique has already been leveraged successfully in various natural language processing (NLP) applications.
Some of the most notable self-supervised NLP models include Word2Vec, GloVE, fastText, BERT, and GPT. These models have demonstrated significantly higher performance than those trained solely through supervised learning. In particular, BERT and GPT have been responsible for significant breakthroughs in NLP, achieving state-of-the-art performance on a range of tasks.
Thanks to these models, self-supervised learning is gaining traction as a viable solution for a range of NLP challenges. From language translation and sentiment analysis to question-answering and chatbots, the potential uses of self-supervised NLP models are practically limitless. With continued research and development, we can expect to see even more exciting applications of self-supervised learning in the NLP space in the years to come.
General technique
Self-supervised learning is a broad category of techniques that span a range of approaches and applications. However, there are a few general techniques that have emerged as key means for achieving self-supervised learning, regardless of the precise application being considered.
The general technique is to predict a part of the input from the whole input. The illustration bellow shows what self-supervised learning aims to do: the system is trained to predict hidden parts of the input (in gray) from visible parts of the input (in green).

In the context of natural language processing (NLP), this might involve hiding part of a sentence and predicting the hidden words from the remaining words. This approach is sometimes referred to as "predicting masked words," and can be thought of as predicting the next most likely word given the context of the sentence.

In Computer Vision, one simple technique involves predicting the rotation of an image or object. This approach involves rotating an image or object at random, and then training the model to predict the correct rotation. This technique allows the system to learn about the intrinsic nature of the image or object itself, rather than simply memorizing the labels applied to it.
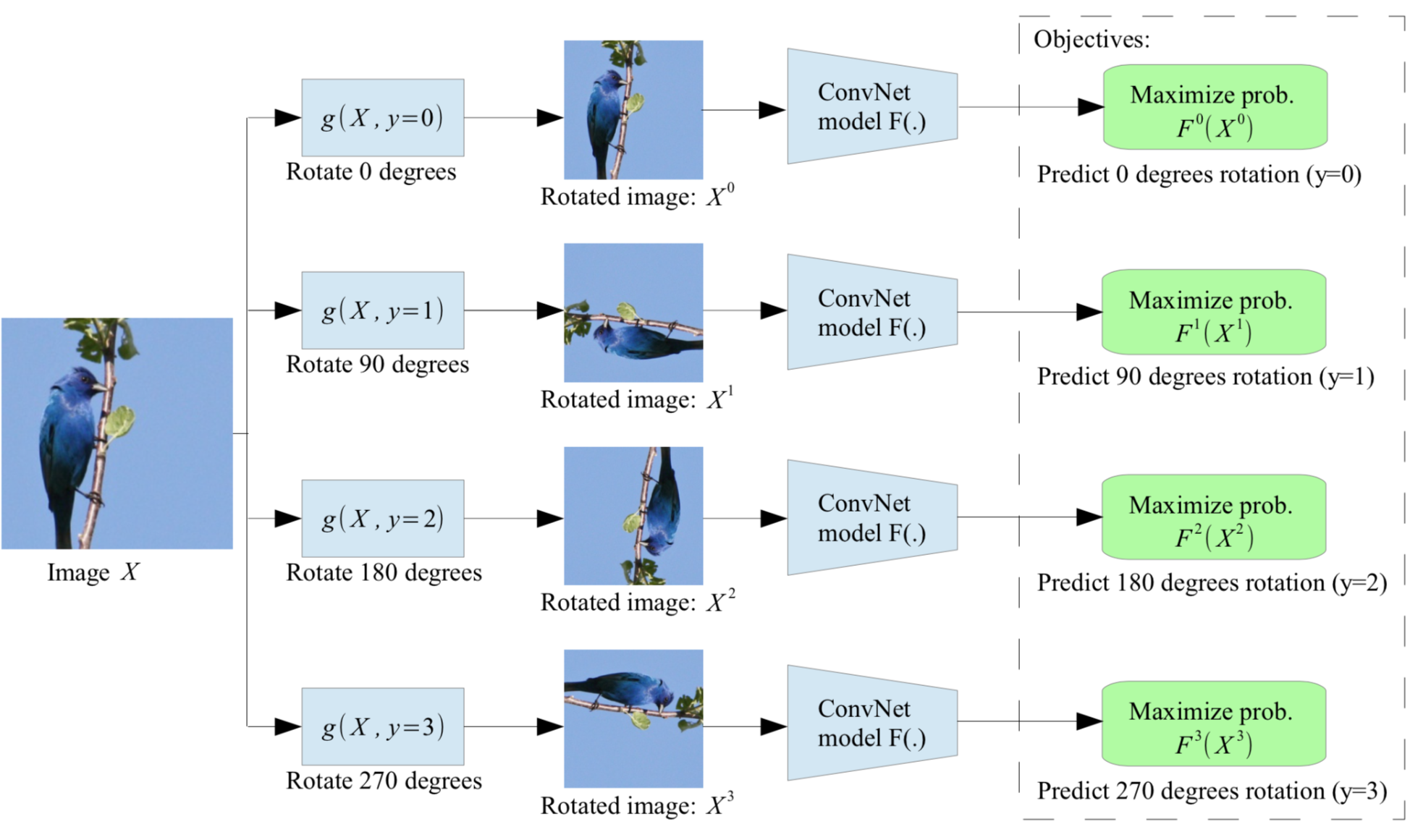
These techniques demonstrate the versatility and adaptability of self-supervised learning approaches. By leveraging such general techniques, researchers and developers can achieve a wide range of self-supervised learning objectives across a range of applications and industries.
Different family of methods
Within the realm of self-supervised learning, there are a number of different families of methods that have been developed and utilized. These methods vary in their specific approach and technique, but all share the overall goal of enabling self-supervised learning without the need for human-annotated labels.
The deep metric learning family is one approach that seeks to encourage similarity between semantically transformed versions of an input. Models trained using this approach aim to learn the underlying structure of the input data, even when that structure is not explicitly labeled or annotated. This method has been used to great effect in models such as SimCLR.
Another common family of self-supervised learning methods is the self-distillation family. This approach involves feeding two different views of the same input to two encoders, and then mapping one view to the other using canonical correlation analysis. This method helps the model to learn the intrinsic structure of the data, even in the absence of human labels.
Finally, the masked image modeling approach involves applying degradations to training images and then training the model to undo these degradations. This can include approaches like predicting masked words in NLP or predicting a rotated image, as discussed earlier. By reconstructing the original input, the model can strengthen its understanding of the underlying pattern or structure within the data.
These different families of self-supervised learning methods demonstrate the diverse range of approaches and techniques that have been developed in the quest to enable AI models to learn without human annotation. With continued research and development, we can expect to see even more exciting applications of self-supervised learning across a range of industries and use cases.
SimCLR
Definition
One of the most exciting recent developments in the field of self-supervised learning is the concept of a simple framework for contrastive learning of visual representations. This approach aims to encourage similarity between two augmented views of an image, without the need for human-annotated labels.
At its core, this framework relies on a range of image transformations - such as random resizing, cropping, color jittering, and random blurring - to create two different views of the same image. The model then learns to identify and strengthen the similarities between these views, using a backbone architecture paired with a projector composed of a multilayer perceptron (MLP) and rectified linear units (ReLU).

Thanks to the simplicity and effectiveness of this approach, the simple framework for contrastive learning of visual representations has become a popular and widely-used approach in the field of self-supervised learning. It has demonstrated impressive results in a range of applications, indicating that it is a powerful technique for enabling models to learn from data without human-labeling. With continued research and development, we can expect to see even more exciting applications of self-supervised learning in the years to come.
Pipeline
The process of implementing contrastive learning of visual representations using the simple framework involves a specific pipeline of steps. This pipeline is designed to enable the model to learn from data without relying on pre-existing labels or annotations.

- First, the model randomly draws examples from the original dataset. It then applies data augmentations in order to create two sets of corresponding views of each example. These augmentations can include transformations such as random resizing, cropping, color jittering, and random blurring, as well as any other relevant techniques.
- Next, the model computes embeddings of the two views using a convolutional neural network (CNN). These embeddings represent the underlying structure of the data and are used to compare the two different views of each example.
- The embeddings are then fed forward into a projector, which consists of a multilayer perceptron (MLP) and rectified linear units (ReLU). The goal of the projector is to strengthen the similarities between the embeddings of the two views and encourage the model to better distinguish between views of different examples.
- Finally, the model is optimized to better distinguish between the two views of the same example and to maximize similarity between the embeddings of corresponding views of different examples. This optimization process fine-tunes the model, improving its ability to learn from data in the absence of human-labeling.
This pipeline represents a powerful and effective approach to enabling self-supervised learning in the field of computer vision. By allowing models to learn from data without human-labeling, we can unlock new possibilities for innovation and problem-solving in a range of industries and applications.
Loss
One of the key components of the simple framework for contrastive learning of visual representations is the loss function used to optimize the model to distinguish between views of the same example and views of different examples. In this framework, the commonly used loss function is InfoNCE Loss.

InfoNCE Loss uses a numerator and denominator to force the positive pairs - that is, two views of the same example - to have greater output values than negative pairs - that is, views of different examples. The numerator is the output of the positive pair, while the denominator is the sum of the output values of both positive and negative pairs.
By forcing the positive pairs to have higher output values than the negative pairs, the model learns to better distinguish between views of the same example and views of different examples. The resulting loss works to push negative pairs apart and force positive pairs together, optimizing the model to better represent the underlying structure of the data.
The InfoNCE Loss function is a critical component of the simple framework for contrastive learning of visual representations. By optimizing the model to better distinguish between views of examples and pushing negative pairs apart, the algorithm can enable self-supervised learning without the need for human-generated labels.
Tips
When implementing the simple framework for contrastive learning of visual representations, there are several tips and best practices that can improve the performance and effectiveness of the model.
Firstly, it's recommended to use a larger batch size than usual when training the model. This can help to improve the stability of the training process and make it more efficient by allowing the model to process more examples simultaneously.
Secondly, using a larger network as the backbone of the model can also be beneficial. This can help to capture more complex features and patterns in the data, allowing the model to learn more effectively in the absence of human-generated labels.
Additionally, it's generally recommended to train the model for longer than usual when implementing the simple framework for contrastive learning of visual representations. Training for 2 to 3 times longer than usual can help to ensure that the model converges to the optimal solution and maximizes its ability to learn from data.
These tips and best practices can help to improve the performance and effectiveness of the self-supervised learning model, enabling it to learn from data without relying on human-generated labels. With continued research and development, we can expect to see even more exciting applications of self-supervised learning within the field of computer vision and beyond.
Experiments Results
It was during the process of updating one of our own AI models that we began to consider the possibilities of self-supervised learning. We were intrigued by the prospect of training a model to learn from data without human-generated labels, potentially unlocking new insights and capabilities we had yet to explore.
Setup
We implemented the new multi-task version of one of our module, supporting these tasks:
- skin segmentation
- scalp segmentation
- blur detection
- skin tone classification
- and relevance classification
We trained a self-supervised learning (SSL) model based on EfficientNet B4, and used it for multi-task learning (MT)
Evaluation was performed using top1 and top5 accuracy metrics to measure the proportion of correctly classified examples in the top prediction results.
Our dataset included 200,000 examples for training and 30,000 examples for validation (~100 GB).
PyTorch 2.0 and PyTorch Lightning 2.0 were used for efficient processing and training.
Distributed Data Parallel on DGX was employed, consisting of 4 A100 GPUs, 40 GB of GPU RAM, 256 GB of system RAM, and 128 CPU cores.
SSL Backbone training
In implementing the SSL model for our experiment, we trained on the full dataset with EfficientNet B4 as our architecture and 1024 hidden layers. Our images were set to a size of 384 pixels.
However, we encountered some challenges during the training process, and the training was killed at around 200 epochs because of a Out of Memory. This error needs some investigation. While the training has not fully finish yet, we still manage to have to promising result by integrating the model as a backbone
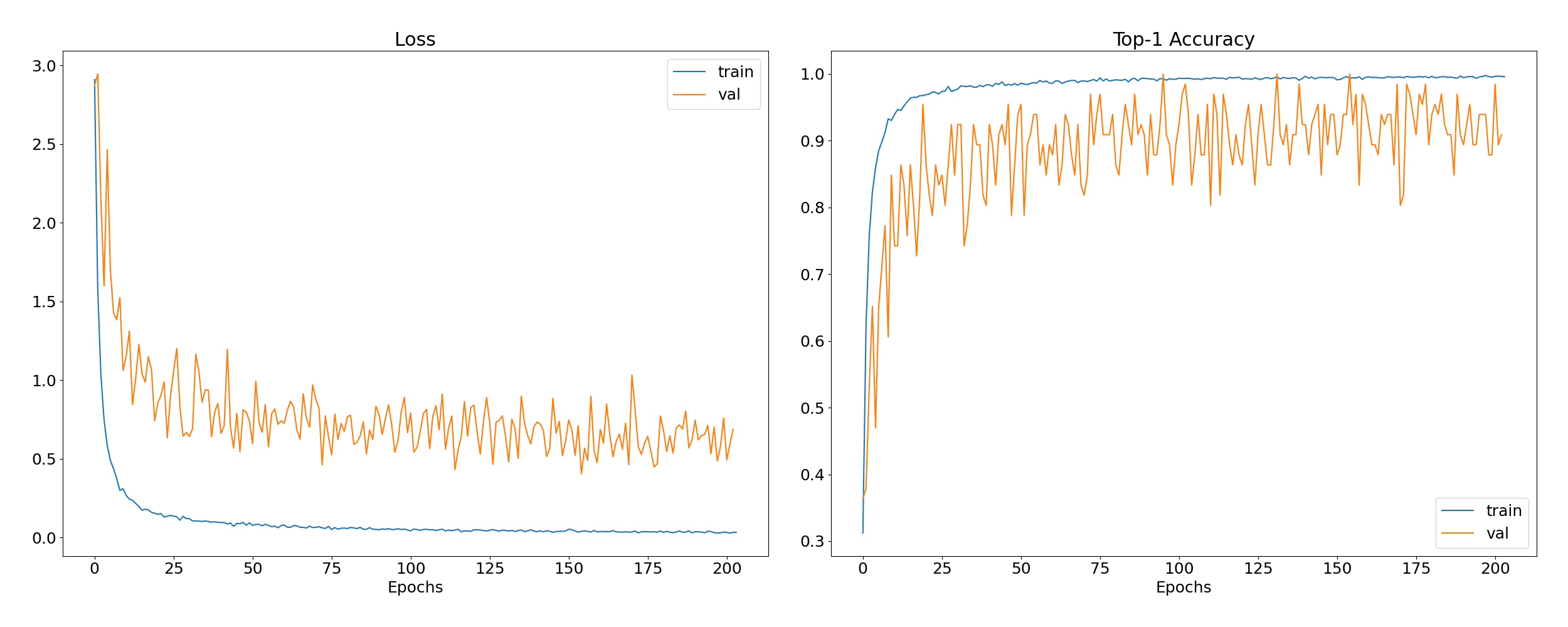
MT vs MT+SSL
For the multi-task model, we trained 2 model that are almost identical in every way except that one is using EfficientNet B4 trained on SSL with our dataset while the other model is using EfficientNet B4 pretrained. Both are from the timm library. In this training, we utilized progressive learning techniques to enhance the performance and accuracy of our multi-task model. Specifically, we adopted a progressive learning approach that began with a smaller image size and then progressively moved to larger image sizes as the model became more proficient at learning from the data.

Task assignment:
- Skin Segmentation
- Scalp Segmentation
- Skin Tone Classification
- Relevance Classification
The global trend here is that the SSL+MT model seems to be either on equal footing with just the MT model or it is better. The training process also seems the be smoother and converge faster. Using a SSL backbone seems to help greatly when doing progressive learning, we can see that the loss increase during the epoch is less pronounce than without using SSL.

By looking at the global loss (sum of all the other), the trend we saw for individual task seems be confirmed here. The SSL+MT model is better and handle change of resolution better.
Conclusion
In conclusion, our experiment with self-supervised learning and multi-task learning showcases the exciting potential of these approaches to unlock new capabilities and insights in computer vision. Our findings suggest that training an SSL model can yield promising results, even with less massive datasets. However, it's crucial to be mindful of the complexities and challenges that come with training these models, especially in terms of resource allocation and management. Nonetheless, with careful attention to training procedures, architecture design, and data management, we believe that self-supervised learning and multi-task learning hold the key to achieving ever more advanced and sophisticated AI models in the future. We look forward to contributing to this exciting field and sharing our findings with the research community.
Reference
- Self-supervised Pretraining of Visual Features in the Wild arXiv:2103.01988v2 [cs.CV] 5 Mar 2021
- A Cookbook of Self-Supervised Learning arXiv:2304.12210v1 [cs.LG] 24 Apr 2023
- A Simple Framework for Contrastive Learning of Visual Representations arXiv:2002.05709v3 [cs.LG] 1 Jul 2020
- Representation Learning with Contrastive Predictive Coding arXiv:1807.03748v2 [cs.LG] 22 Jan 2019
- https://ai.facebook.com/blog/self-supervised-learning-the-dark-matter-of-intelligence/ Yann LeCun VP and Chief AI Scientist
- https://lilianweng.github.io/posts/2019-11-10-self-supervised/
- https://amitness.com/2020/02/illustrated-self-supervised-learning/
- https://lightning.ai/docs/pytorch/stable/notebooks/course_UvA-DL/13-contrastive-learning.html
- https://sthalles.github.io/simple-self-supervised-learning/
- https://ai.googleblog.com/2020/04/advancing-self-supervised-and-semi.html


Member discussion