
Sapiens: Foundation for Human Vision Models

A group of researchers at Meta just published their work on a vision model, specifically build for analysis of images with humans. The main idea is to pre-train a model with millions of human images without annotations, for some simple task. Then fine-tune the model for each desired task. This second step still requires annotations, however less annotation and diversity is required to obtain a better result.
Sapiens - a pre-trained model
The model is a classic encoder-decoder. It starts from an image and a convolutional neural network (CNN) encode the image into a smaller dimension. A decoder increase back the dimension to the original size. The main goal was to obtain a model satisfying the following criteria:
- Generalisation: Ensure that the model woks well with unseen or new conditions.
- Broad applicability: Suitable for a lot of tasks with little adaptation.
- High fidelity: A precise high quality output.
On the other hand the speed and size of the model was not a significant criteria. The largest Sapiens model has two billions parameters and requires 8.7 trillions floating point operations in order to analyse one image. For comparison iBOT, also a pre-trained model, based on ImageNet21k requires only 17 billions floating point operations, which is about five hundred time smaller.
In order to train a model, a task is required. The author chose the masked auto-encoder (MAE) approach. It is rather simple and has been already used for various application. The idea is the following: train the model to fully reconstruct an image from a partially masked version. As illustrated below the model is able to reconstruct rather well an image when shown a version where 75% is hidden.

When almost the whole picture is hidden the model is still able to reconstruct an image decently. Although in this case a lot of artifact can be seen on the result. As illustrated below, it is even hard to guess the subject of the picture from the masked version.
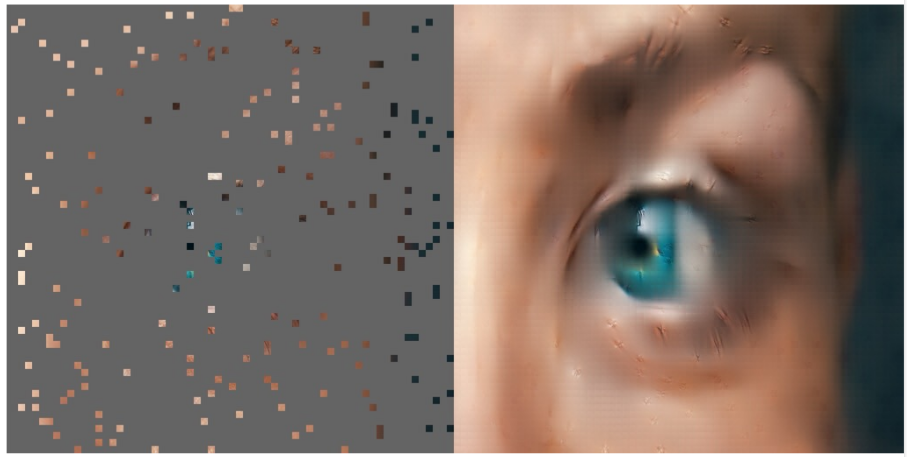
The pre-trained model has to be train first. For this the researcher made and used Human-300M a database with 300 millions images with humans. The model was trained for 18 days on 1024 A100 Nvidia graphic cards. The images are resized to a resolution of 1024×1024.
Once the main model is trained, it is time for application. The authors fine-tune the pre-trained model with four examples of tasks. Of course other tasks could be done, but those illustrate well the possibilities.
- Pose estimation.
- Full body segmentation.
- Depth map.
- Normal map.
Pose estimation
Given an image with a human, find various key points: each eyes, elbows, hands; fingers, foots, and so on. In total the model is able to find 308 key points: 243 for the face, 40 for the hands and 25 for the rest of the body. This allows to have a good understanding of the overall position of the body, the hands and the expression on the face as several key-points are around the mouth and the eyes.
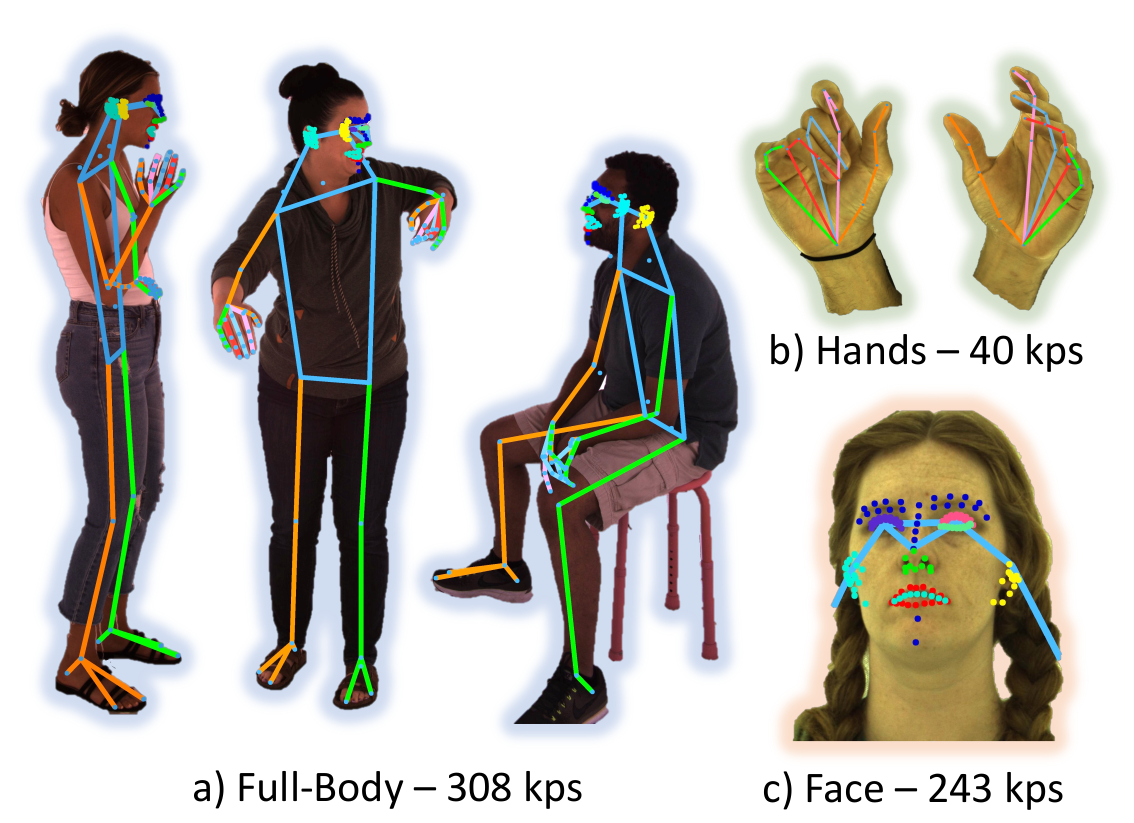
The authors use an heatmap prediction approach: one heatmap per key-point, where the value at a pixel represent the probability that the given key point is here. This give a total of 308 predicted heatmap, which is big. The model is based on the pre-trained model. They start with the weight of the encoder, and start with random values for the decoder. In addition the model was trained with an in-house dataset of one million images, which was made using a capture system.
Although the training set is taken from a unique source and has not much variety, thanks to the pre-training the model obtains state of the art result on the test set Human-5K. With a rather large improvement.
Full body segmentation
A second classical task is to segment various part of the body on one image. Sapiens can also be fine-tuned for that. The model is able to segment 28 different zone: hairs, head an neck, each hand, each foot. Below is an illustration of segmentation task:

The model predict one heatmap per zone. Once again the encoder start from the pre-trained encoder and the decoder is randomly initialized. In addition 100k fully segmented images are used for fine-tuning. Once again the results are good. It largely beat state of the art model, with a mean intersection over union of 81% compared to 64% for previous state of the art solution. Although the comparison is unfair as the previous model was meant for general segmentation and not full body segmentation.
Depth and normal maps
The last two example of tasks are the computation of depth map and normal map. The depth map give the relative distance to the camera of each pixel in the image, the normal map give the normal vectors to the corresponding surface. Both depth map and normal map are heavily used in computer 3D graphics.

It is very hard to annotate the depth map of an image and even harder for normal map. In order to obtain a training set the authors use 600 high quality real human scans, then place them in a virtual environment and took virtual pictures in order to obtain 500k rather realistic images. As the image are computed it is easy to also compute the depth map and the normal map, hence obtaining a fully annotated dataset.
The integration is not perfect as illustrated above the people seems to be floating and not really in the image. However thanks to the pre-training of Sapiens, the model obtains good result on real images. Obtaining once again state of the art result both on depth map and normal map estimation. Although once again the comparison is unfair, as Sapiens model is specifically train for human and is compared to model trained for general depth and normal map computation.
Reference:
- R. Khirodkar, T. Bagautdinov, J. Martinez, S. Zhaoen, A. James, P. Selednik, and S. Anderson, S. Saito, Sapiens: Foundation for Human Vision Models, 2024, arXiv 2408.12569, https://arxiv.org/abs/2408.12569