
The Skin Game: Setting New Standards for AI in Dermatology
Introduction
Artificial intelligence has made significant strides in dermatology, promising faster and more accurate skin disease detection. However, one critical issue remains the lack of standardized evaluation methods for AI models for dermatology applications. Performance metrics can be misleading without proper benchmarking, making it difficult to assess which models truly excel in clinical settings. A recent research paper, "The Skin Game: Revolutionizing Standards for AI Dermatology Model Comparison," [1] aims to tackle these inconsistencies and proposes a robust framework for model evaluation.
Methodology
The study examined the current landscape of AI-based dermatology research and identified key methodological flaws that hinder model evaluation. A systematic review of recent studies highlighted the most common pitfalls, including:
- Data Leakage: Some studies perform data augmentation before splitting datasets into training and testing sets, inadvertently introducing information from test samples into the training process, leading to overly optimistic results.
- Validation vs. Test Data Confusion: Many researchers report performance based on validation datasets rather than independent test datasets, inflating AI performance metrics and limiting real-world generalizability.
- Lack of Standardized Metrics: Performance metrics such as accuracy are often reported without additional context, whereas more informative metrics like F1-score, precision, recall, and area under the curve (AUC) are inconsistently applied across studies.
To counter these issues, the authors propose a rigorous evaluation framework based on four essential components:
- Standardized Preprocessing:
- Images should be uniformly resized and normalized to ensure consistency.
- Data augmentation should be applied only after dataset splits to prevent data leakage.
- Standard protocols for dataset cleaning, such as duplicate removal and noise reduction, should be established.
- Rigorous Dataset Splitting:
- AI models should be evaluated on completely unseen test data.
- Stratified sampling should be used to maintain class balance during splits.
- Proper cross-validation techniques (e.g., 5-fold cross-validation) should be implemented to obtain a robust performance estimate.
- Comprehensive Performance Metrics:
- Instead of relying solely on accuracy, models should be assessed using macro-averaged F1-score, precision, recall, and AUC.
- Confusion matrices should be analyzed to understand model biases and failure patterns.
- Statistical significance tests should be conducted to ensure that performance differences are meaningful rather than due to random chance.
- Explainability and Transparency:
- Attention maps should be employed to visualize how models make predictions.
- High-confidence misclassifications should be analyzed to detect potential biases.
- Interpretability tools such as Grad-CAM and SHAP should be integrated into AI evaluations.
Results
The study evaluated the DINOv2-Large [2] vision transformer model on three benchmark dermatology datasets—HAM10000 [3], DermNet [4], and ISIC Atlas [5]. The model demonstrated strong performance overall, with macro-averaged F1-scores of 0.85, 0.71, and 0.84, respectively. However, certain skin conditions, particularly melanoma and bacterial infections, remained challenging due to their similarity with benign lesions and variable clinical presentations.
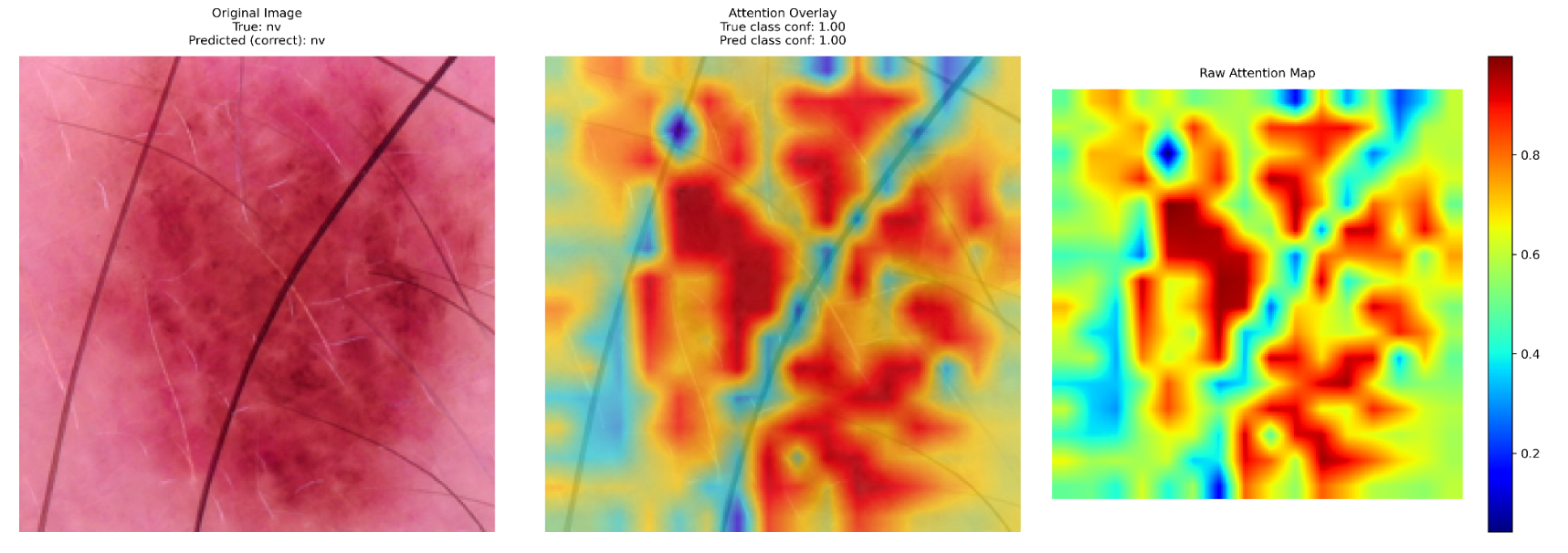
A critical aspect of the study was explainability, where attention maps were used to interpret the model's decision-making process. Key insights included:
- Lesion Localization: The model effectively highlighted relevant areas in correctly classified cases, reinforcing confidence in its decision-making.
- High-Confidence Misclassifications: Some cases, particularly melanomas misclassified as benign nevi, showed strong but incorrect predictions, emphasizing the need for human oversight.
- Bias Detection: Variations in lighting, skin tone, and lesion presentation impacted the model's predictions, highlighting the necessity of diverse and representative training data.
These findings underscore the importance of integrating explainability tools in AI dermatology research. By visualizing decision-making processes, researchers and clinicians can better understand where AI models succeed and fall short, ultimately improving model reliability and safety in real-world applications.
Conclusion
The study highlights the urgent need for standardized evaluation protocols in AI-driven dermatology. Without a structured framework, models may produce misleading performance claims, hindering clinical adoption.
AI models can become more trustworthy and clinically viable by addressing data handling inconsistencies, enforcing proper dataset splits, and integrating explainability techniques. The paper’s recommendations provide a strong foundation for researchers and developers to improve model reliability, ensuring that AI in dermatology meets the highest standards of accuracy and transparency.
References
[1] Miętkiewicz et al. The Skin Game: Revolutionizing Standards for AI Dermatology Model Comparison, February 2025
[2] Oquab et al. DINOv2: Learning Robust Visual Features without Supervision, April 2023
[3] Tschlandl et al. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions, August 2018
[4] Bajwa et al. Computer-aided diagnosis of skin diseases using deep neural networks, 2020
[5] Rafay et al. EfficientSkinDis: An EfficientNet-based classification model for a
large manually curated dataset of 31 skin diseases, 2023