
ViTPose : A simple yet powerful transformer baseline for Human Pose Estimation

Human Pose Estimation is a critical task in computer vision, with applications spanning from medical diagnostics and biomechanics analysis to surveillance, augmented reality and robotics.
The challenge ? Precisely localizing human anatomical keypoints despite occlusion, truncation, and variations in appearance, ideally in real-time. It requires a robust model to capture relationships between different joints and able to adapt to various image resolutions.
While CNNs have been the go-to approach for years, their inherent limitations in capturing long-range dependencies call for a paradigm shift. This blog presents ViTPose, a simple yet powerful Vision Transformer (ViT) baseline that achieves SOTA performance on COCO test set with a plain, non-hierarchical architecture.
Why Vision Transformers ?
Traditional CNN-based methods struggle with:
- capturing global relationships between joints
- complex architectures requiring multiple processing stages
- adapting to complex posture variations
- limited flexibility and scalability
ViTs address these challenges by leveraging global attention, making them easier to scale across different model sizes while offering superior performance with simpler architectures.
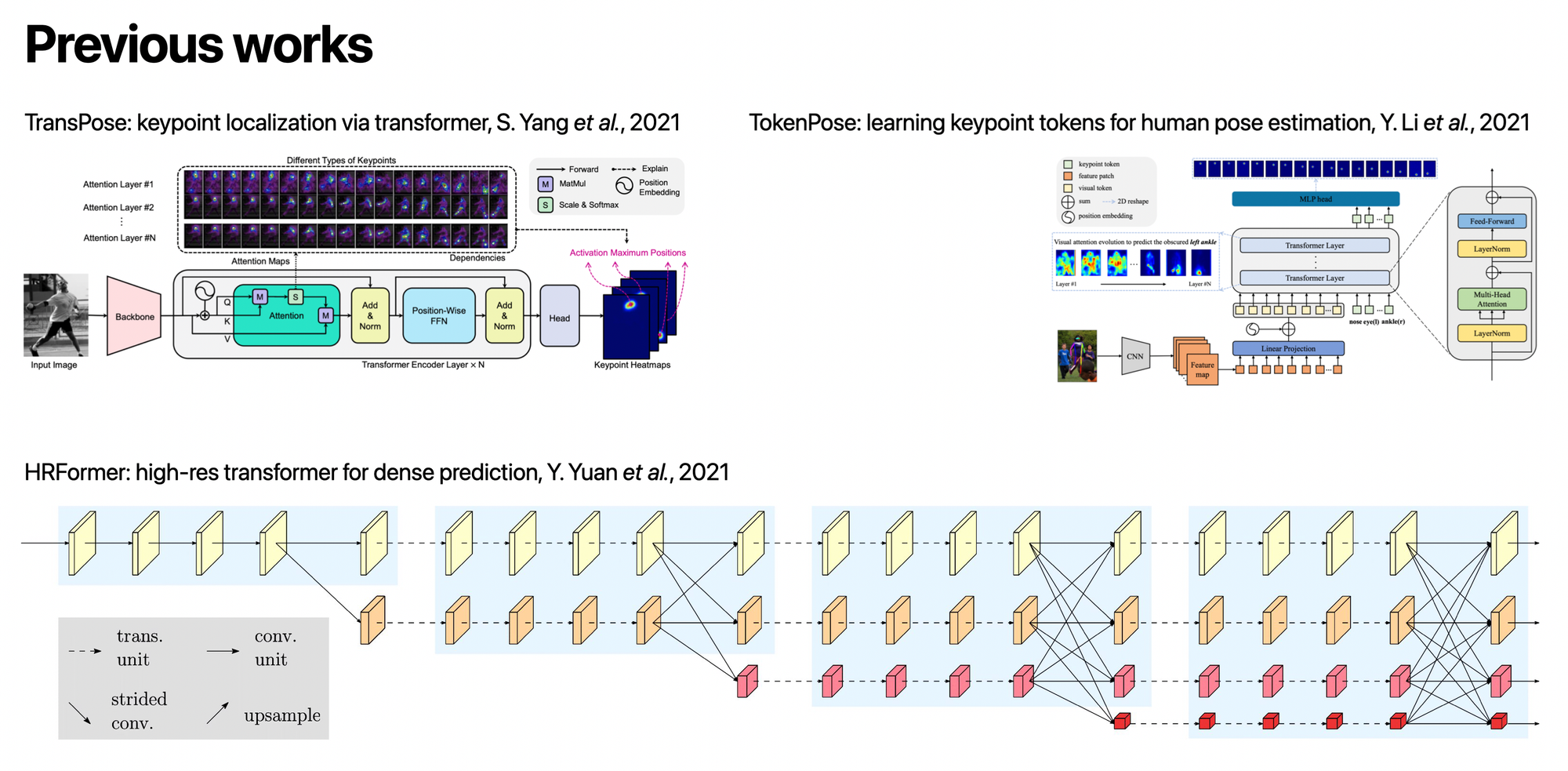
Despite existing transformer-based approaches relying on CNN feature extractors, ViTPose demonstrates that a plain ViT can be highly effective for pose estimation.
ViTPose overview
ViTPose is designed to be:
- Simple : a plain, non-hierarchical transformer architecture
- Scalable : ranging from 100M to 1B parameters, adapting to different computational needs
- Flexible : works with different training strategies, attention mechanisms, datasets, and resolutions
- Transferable : knowledge from larger models can be distilled into smaller models
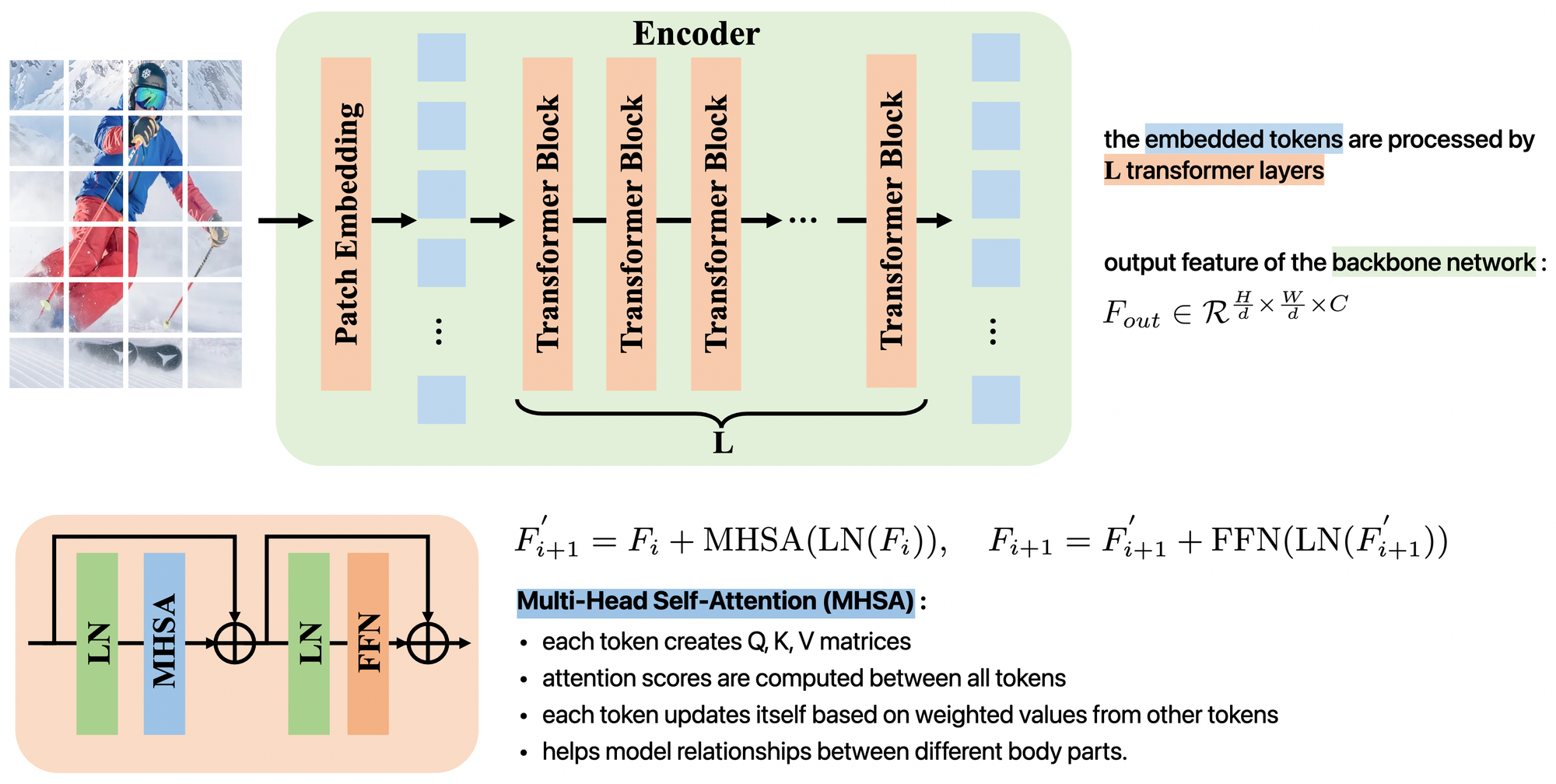
ViTPose simple architecture
Encoder : plain, non-hierarchical transformer
- Input : images of size H*W*3 are divided into patches of size H/d * W/d * 3
- Embedding : patches are embedded into tokens of dimension H/d * W/d * C
- Multi-Head Self-Attention (MHSA) : models relationships between joints
- Transformer layers : tokens pass through multiple transformer layers
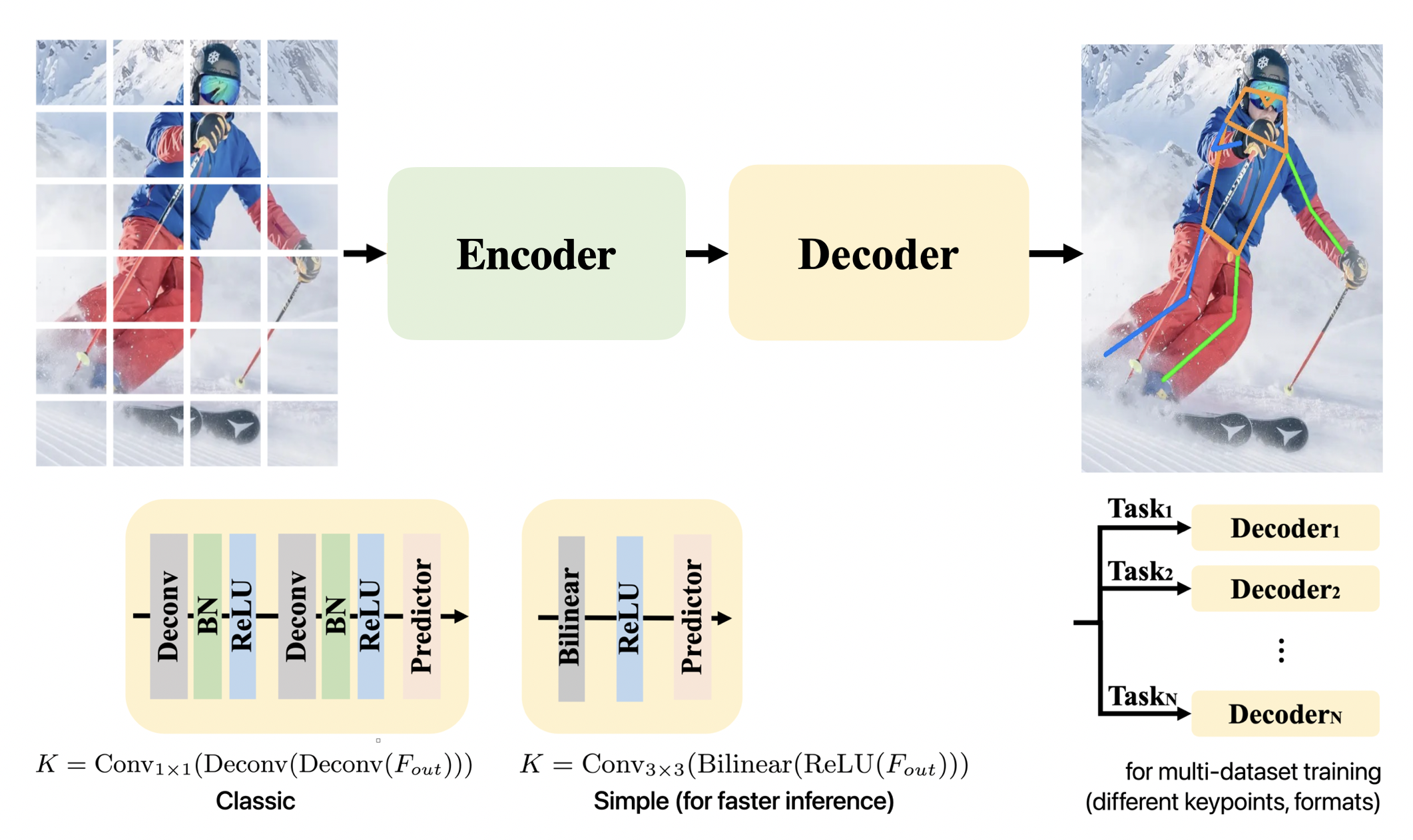
Decoder : extracted features are processed into localization heatmaps for keypoints and ViTPose offers two lightweight decoder variants. ViTPose also handles different datasets with multiple decoders.
Scaling ViTPose
ViTPose scales by modifying the number of transformer layers and feature dimensions. For a 256×192 input resolution, different model variants include :
- ViTPose-B (Base) : 86M parameters
- ViTPose-L (Large) : 307M parameters
- ViTPose-H (Huge) : 632M parameters
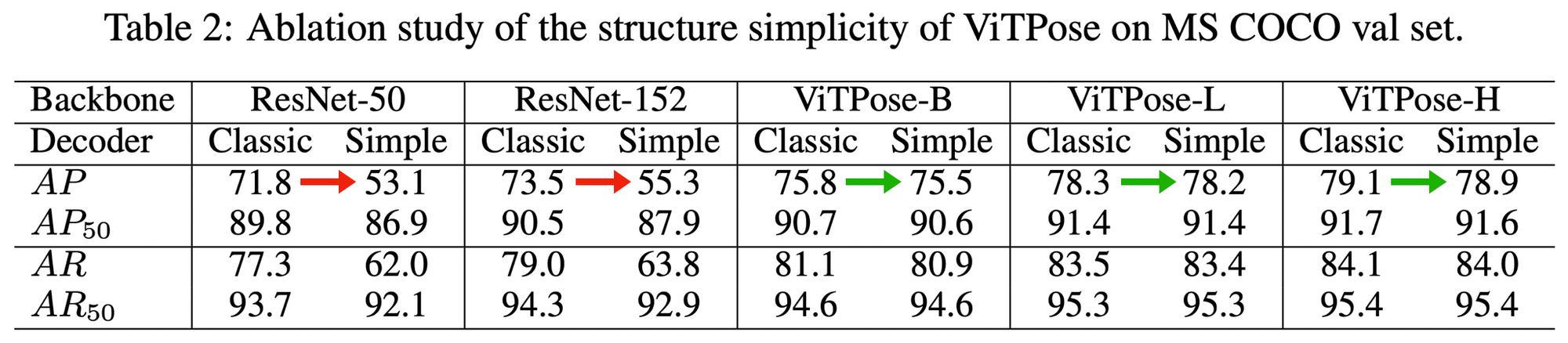
ViTPose Flexibility
Pre-training Strategies : ViTPose achieves comparable performance using pose-specific pre-training and ImageNet pre-training.

Resolution Scaling : increasing input image size and reducing downsampling improves performance consistently.

Efficient attention mechanisms : computing full self-attention across all image patches is computationally expensive.
ViTPose explores alternative attention strategies:
- Full attention: high accuracy but computationally heavy
- Window attention : applies self-attention within small windows
- Shifted-window attention : alternates standard and shifted windows across layers to improve cross-window interactions
- Pooling-window attention : pooled summary tokens maintain global context with reduced computation
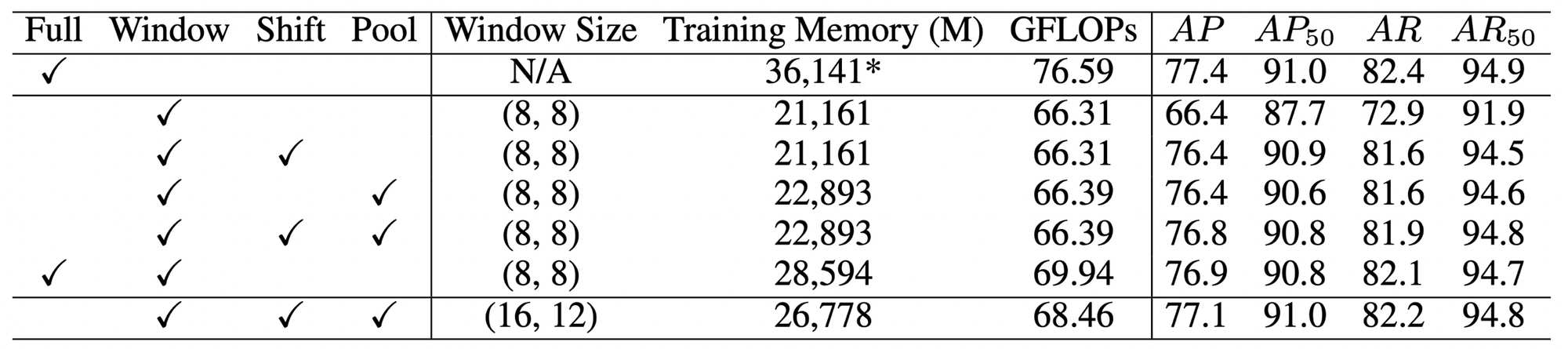
Fine-tuning strategy : ViTPose achieves strong performance even when only fine-tuning selective layers, such as freezing the MHSA module.

Tasks : multiple decoders without much extra cost to handle multiple pose datasets by sharing the same encoder

ViTPose Transferability
ViTPose employs Knowledge Distillation (KD) to transfer information from large models to smaller ones.
- Output (heatmap) distillation : transfers final layer outputs.
The loss is a MSE between the outputs from the student network and the teacher network given the same input. - Token-based distillation : introduces a learnable knowledge token into the teacher model, later used to guide the student model.
The loss is a MSE between the ground truth and the output from the student network that uses the image and the (frozen) trained knowledge token as input.
The final student loss is a combination of heatmap loss and token loss.

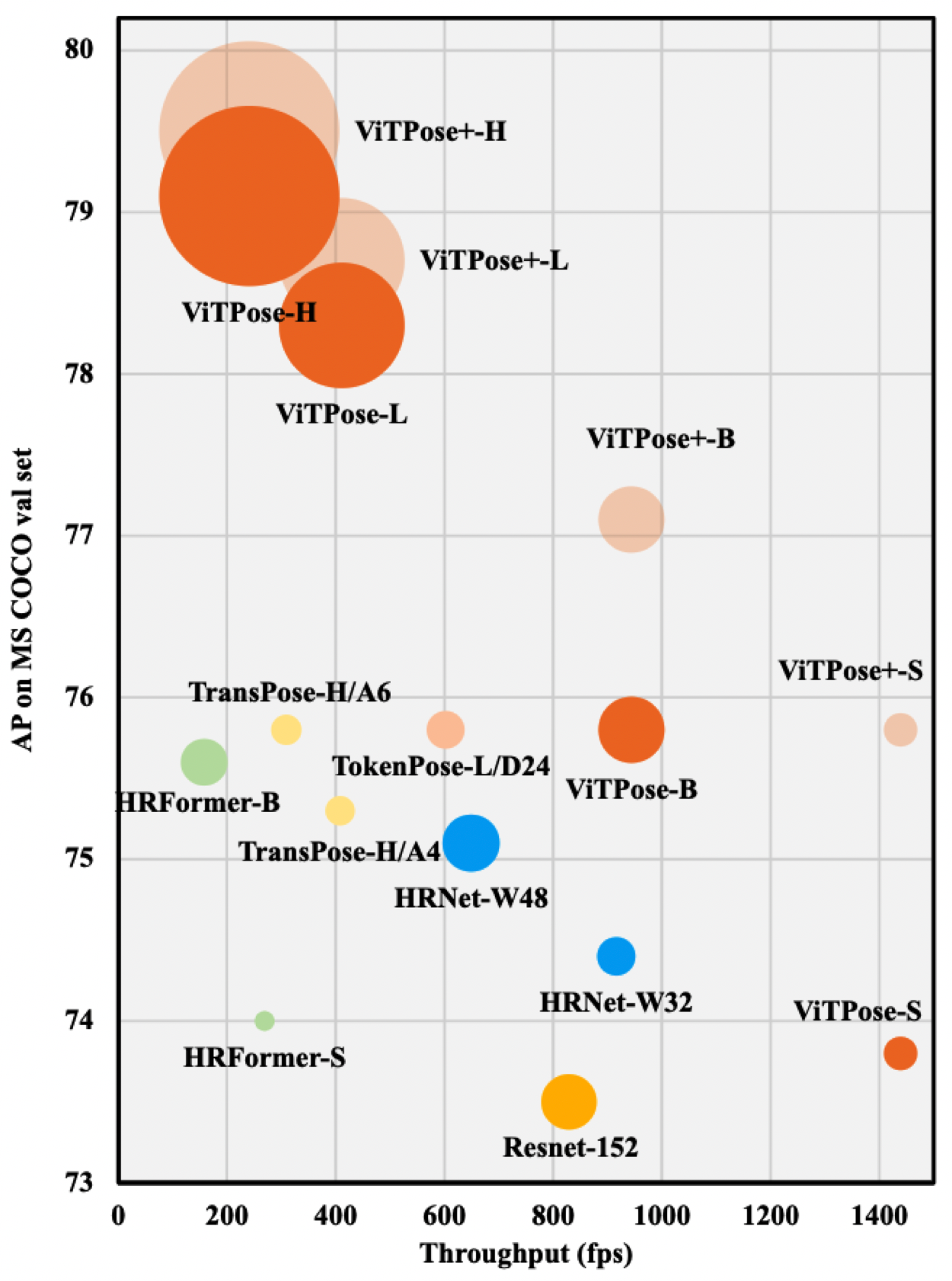
Comparison with SOTA Models
ViTPose outperforms the CNN-based architectures and hybrid CNN-transformer models, achieving higher accuracy with optimized inference time.
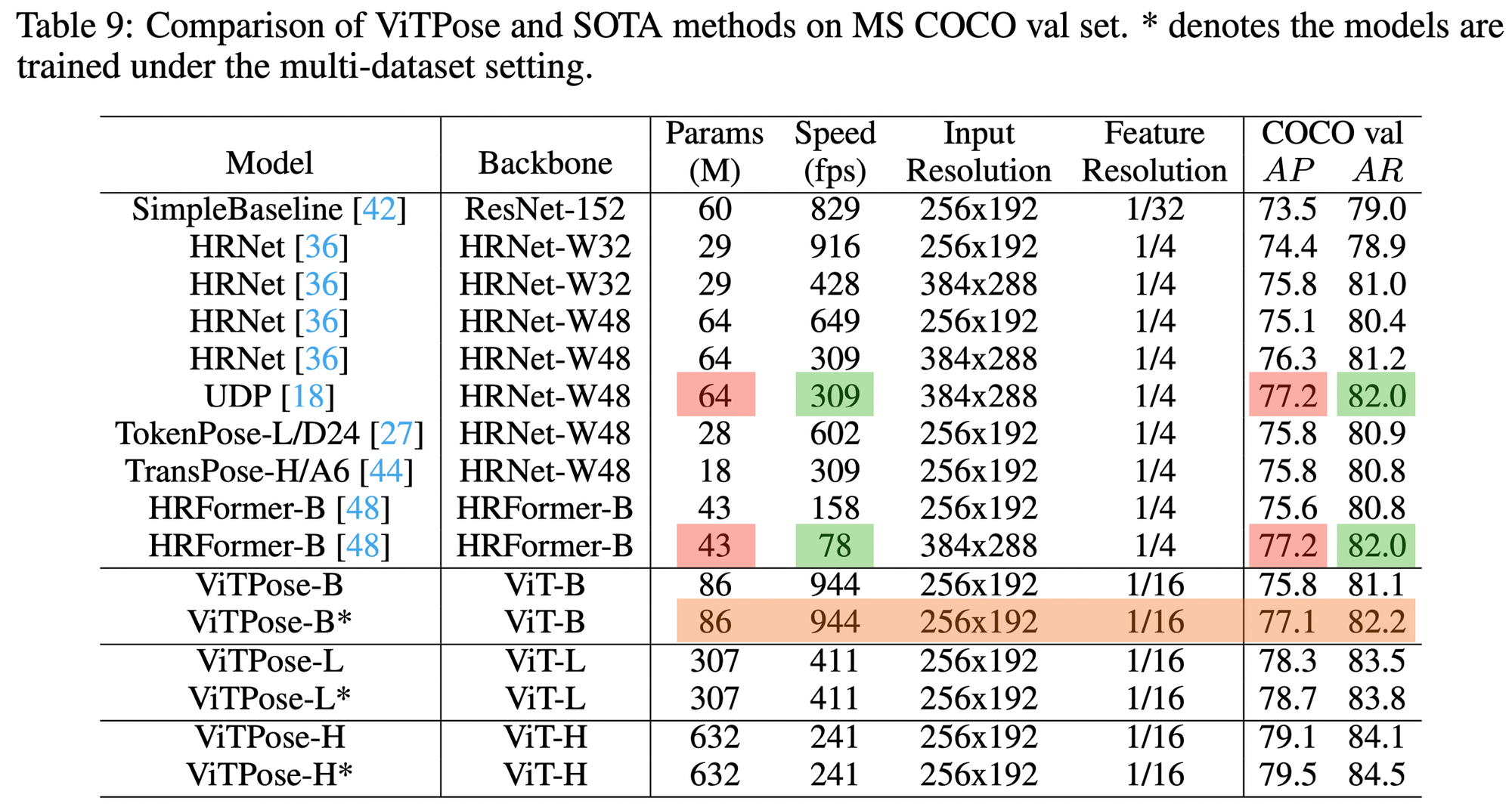
Limitations & direction for Skeleton project
One notable limitation of ViTPose is its performance on body-part images; it struggles with partial inputs, much like other non-finetuned models.
However, one potential direction involves using a trained model to progressively annotate large-scale datasets for Skeleton project.