
Wavelet Diffusion Models are fast and scalable Image Generators
In today's blogpost, we will discuss about a recent paper published in the CVPR 2023 conference by VinAI research team : WaveDiff [1]. This paper aims to accelerate the sampling process of the diffusion models while maintaining good generation quality.
Paper and code are available at this link.
Introduction
This paper introduces a novel approach to image generation using diffusion models enhanced by wavelet transforms. The primary motivation behind this research is to address the slow training and inference speeds typically associated with diffusion models, making them more practical for real-time applications.
How do Diffusion models work ?

A diffusion model is a generative model that learns to reverse a gradual noising process applied to data. Initially, Gaussian noise is progressively added to the data over many steps until it becomes nearly pure noise. The model is then trained to predict and remove this noise step-by-step, effectively denoising the data and generating new samples from the learned distribution. The process involves two key phases:
- the forward diffusion process (adding noise)
- the reverse denoising process (removing noise to generate new data).
The training and inference slowness is mainly due to the high number of steps (for eg. 600, 1000) usually chosen for diffusion process.
Wavelet-transform enhancement

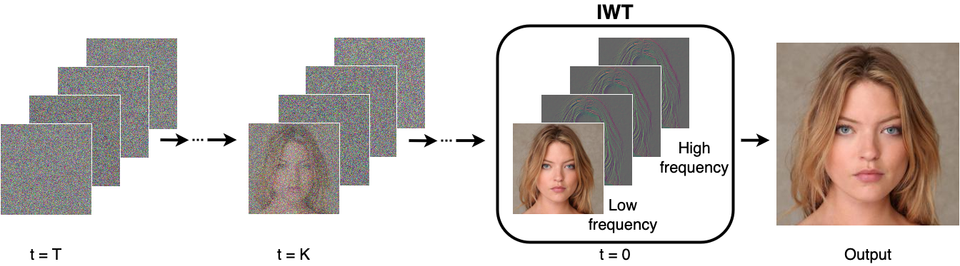
The key innovation in this paper is the integration of wavelet transforms into the diffusion process. The wavelet transform decomposes input images into low-frequency (approximation) and high-frequency (detail) components.
- It enables the model to focus on the high-frequency details, which are crucial for generating high-fidelity images.
- It reduces the spatial dimensions of the data, leading to a significant reduction in computational complexity and faster processing times.
Denoising Diffusion GAN architecture
The authors build their method on the DDGAN [2] framework , where they apply the wavelet transform to both images and feature maps. By performing the diffusion process in the wavelet domain instead of the pixel domain, they leverage high-frequency information more effectively and reduce the overall computational load. This results in faster and more scalable image generation.
Wavelet-embedded generator
Additionally, the paper introduces a wavelet-embedded generator, which incorporates wavelet information at multiple stages within the network to enhance the quality and sharpness of the generated images :
- in the downsampling blocks
- in the upsampling blocks
- in the bottleneck blocks

Results
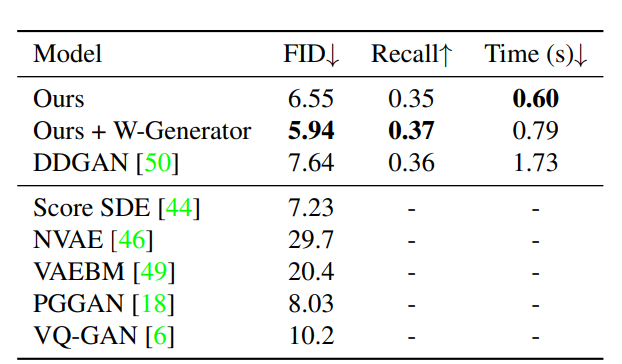
The table below demonstrates the effectiveness of WaveDiff in terms of speed (Time) compared to DDGAN but also in terms of generated images quality (FID).


References
[1] Phung, H., Dao, Q., Tran, A.: Wavelet diffusion models are fast and scalable image generators. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10199-10208. IEEE, Vancouver (2023)
[2] Zhisheng Xiao, Karsten Kreis, and Arash Vahdat. Tackling the generative learning trilemma with denoising diffusion gans. In International Conference on Learning Representations, 2022