
Data Augmentation in Classification and Segmentation: A Survey and New Strategies

In computer vision, deep learning models have proven instrumental in tackling various tasks, from object detection and segmentation to image classification and analysis. However, these models often demand high-quality data to achieve optimal performance. This brings us to data augmentation, a technique that artificially expands the training dataset by creating new variations of existing images.
Data augmentation plays a crucial role in combating overfitting, a phenomenon where a model becomes overly reliant on the specific training data and fails to generalize well to unseen data. By introducing diverse variations into the training set, data augmentation forces the model to learn more robust features and improve its generalizability.
What are the Different Types of Data Augmentation Techniques?
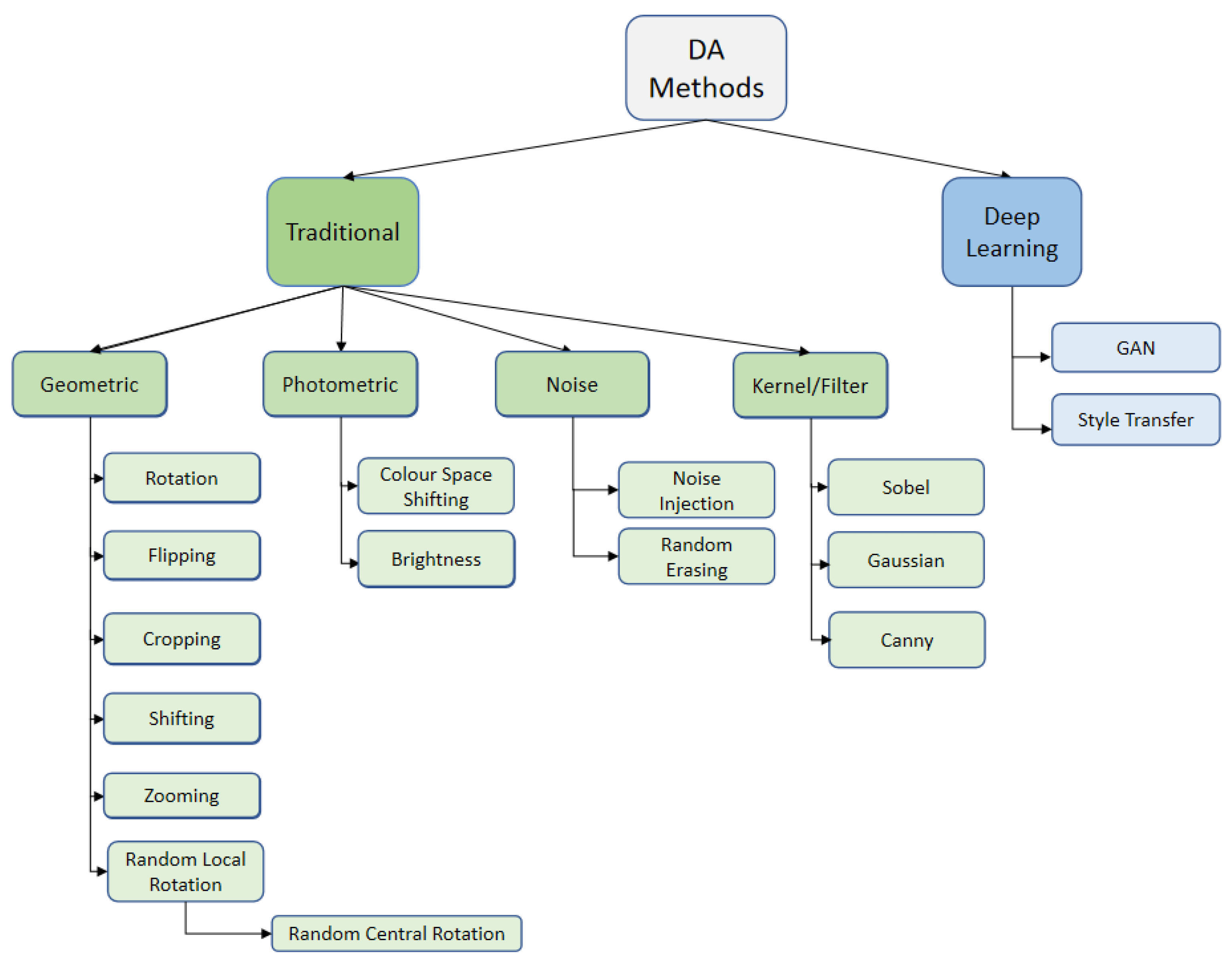
Geometric Transforms
These transformations modify the physical appearance of images, including translation, rotation, scaling, and shearing. This helps the model learn features invariant to these transformations, making it more robust to variations in object position, orientation, and size.

Photometric Transforms
These transformations manipulate the color properties of images, such as brightness, contrast, saturation, and hue. This helps the model learn features invariant to lighting conditions and color variations, making it more robust to real-world scenarios.

Noise Addition
This technique introduces random noise to images, simulating real-world imperfections and enhancing the model's ability to handle degraded data. This can be particularly useful for tasks like object detection and segmentation.

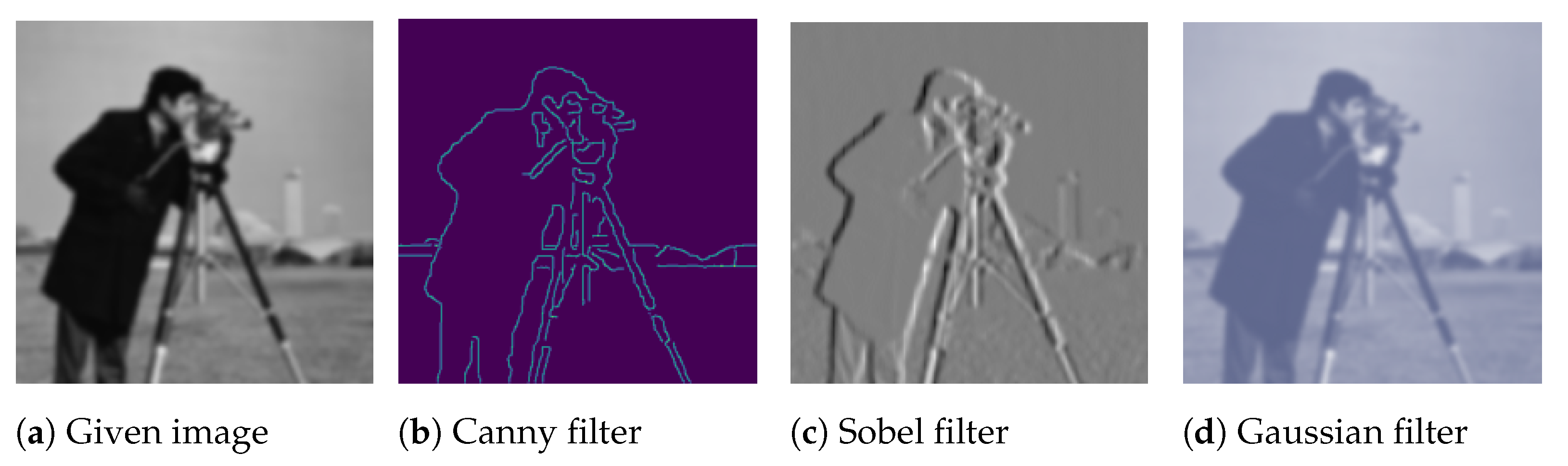
Kernel/Filter-based Transforms
These transformations apply filters to images to create new variations. This can be used to introduce more complex variations that are not easily captured by other methods.
Deep Learning Methods
These methods use deep learning models to generate new images from existing ones. This can be used to create realistic and diverse variations that can help the model learn more sophisticated features.

Unveiling Random Local Rotation (RLR)
RLR is a novel data augmentation technique designed for rotating images without introducing black regions near image boundaries. Unlike traditional rotation methods, RLR selectively turns a circular region within the image, preserving the overall structure and reducing boundary artifacts.
Working Principle of RLR
RLR operates by randomly selecting a circular region in the image and rotating it at a random angle. The size of the circular area can be controlled by specifying a minimum and maximum radius. This process is repeated multiple times to generate a set of augmented images.
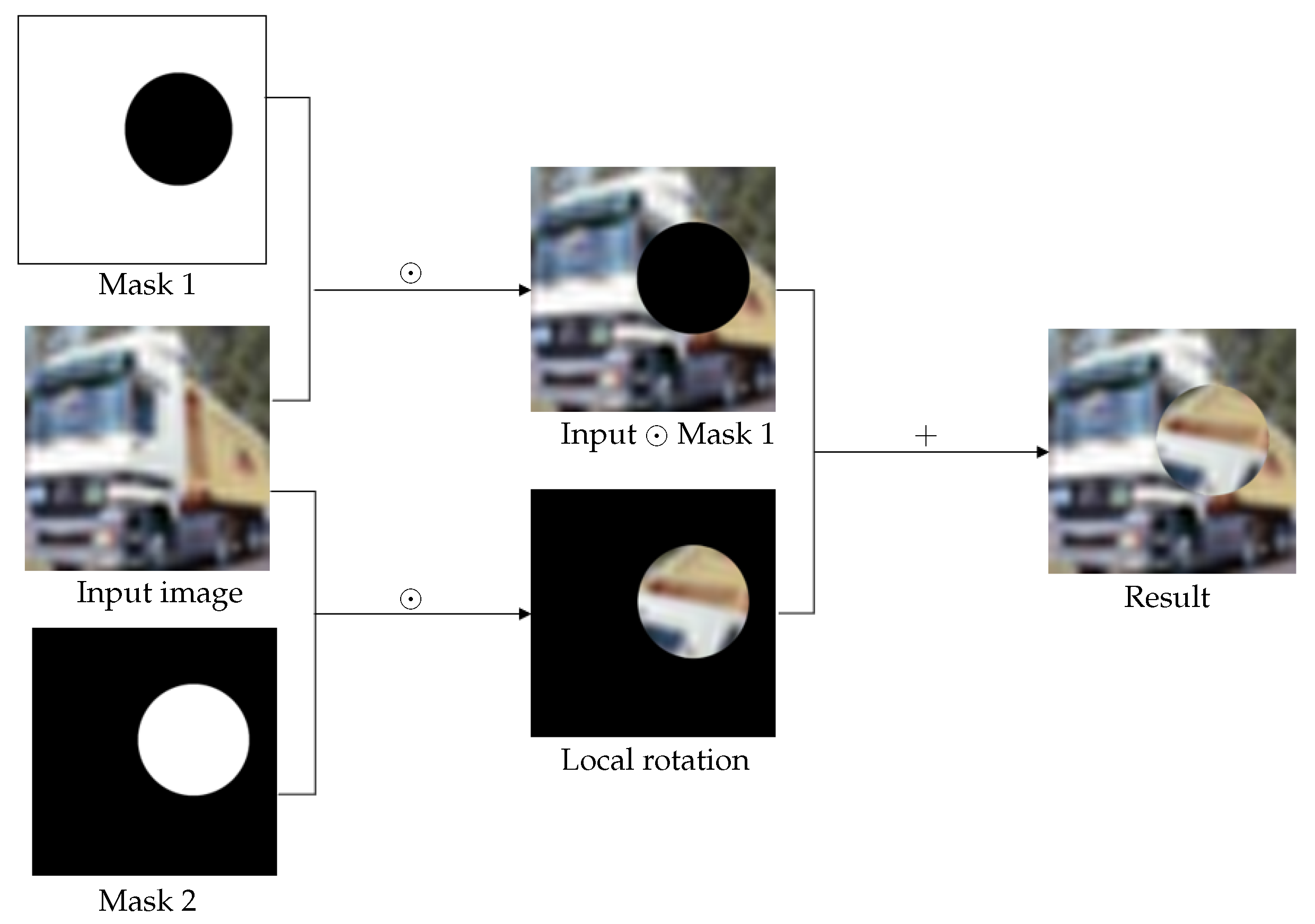
Benefits of RLR
RLR offers several advantages over traditional rotation methods:
Preserves Image Structure: RLR rotates a circular region within the image, preventing the introduction of black regions near image boundaries and maintaining the overall structure of the picture.
Reduces Boundary Artifacts: RLR minimizes the formation of jagged edges and artifacts at image boundaries by rotating local regions rather than the entire image.
Easy to Implement: RLR is straightforward and can be incorporated into existing deep learning frameworks with minimal effort.
Improved Model Performance: RLR has been shown to improve the performance of deep learning models on various computer vision tasks, such as image classification.

Applications of RLR
RLR can be applied to various computer vision tasks where image rotation is beneficial, including:
Image Classification: RLR can enhance the model's ability to recognize objects in images with varying orientations.
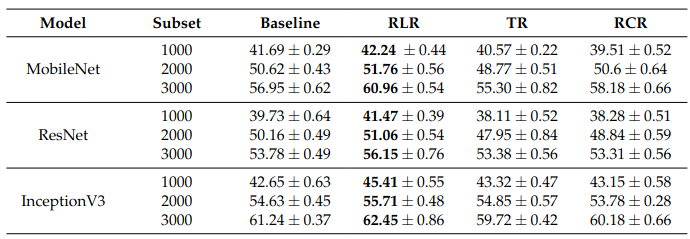
Segmentation: RLR can improve the segmentation quality of objects in images by introducing variations in object position and orientation. It also can be slightly poorer if the segmented objects heavily rely on their shape or position within the image rather than their color or texture.

Overall, RLR is presented as a data augmentation technique that can effectively improve the performance of deep learning models in various computer vision applications, mainly on classification tasks. Its ability to preserve image structure, reduce boundary artifacts, and introduce diverse rotations makes it a valuable tool for enhancing model generalizability and performance.
[1] Alomar K, Aysel HI, Cai X. Data Augmentation in Classification and Segmentation: A Survey and New Strategies. Journal of Imaging. 2023; 9(2):46. https://doi.org/10.3390/jimaging9020046


Member discussion