
EfficientNetV2: Smaller Models & Faster Training
#CNN #EfficientNet #model scaling #progressive learning
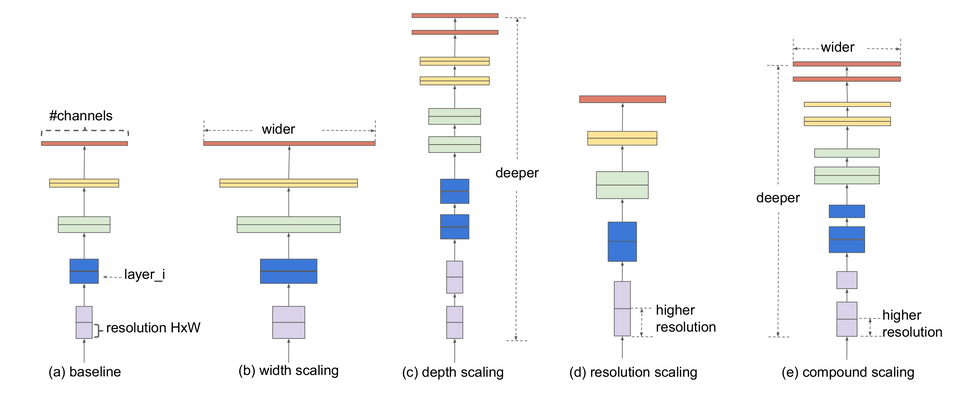
Model scaling
EfficientNet was first proposed in the original paper of Mingxing Tan & Quoc V Le in 2019, namely EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. It introduced a novel model compound scaling method which resulted in a family of efficient neural networks with the baseline model as EfficientNet B0 and scaled up to EfficientNet B1 to B7.

Model scaling is widely used to get better accuracy. Intuitively, higher resolution will enable the model to have higher capacity. A deeper network with more layers will increase the receptive field. More channels will capture more fine-grain patterns. Before the introduction of EfficientNet, it was common to scale up a single dimension of the network: width, depth or resolution. However, the accuracy gain diminishes when model gets bigger. The authors of EfficientNet introduced the compound scaling method that balances all the three dimensions and yields a new family of models which achieve much better accuracy and efficiency.
MBConv and Fused-MBConv
Bottleneck convolution block was first introduced in the original paper of ResNet in 2015. This convolution block shrinks the input channels, hence the name bottleneck. MBConv is the inverted bottleneck convolution block, where the channels are expanded instead. This type of convolution block was proposed in the MobileNetV2 paper in 2018, hence the name mobile inverted bottleneck convolution or MBConv for short.

Fused-MBConv block is similar to MBConv, except the depthwise separable convolution is replaced by standard 2D convolution. Depthwise convolution has fewer parameters and FLOPS compared with standard 2D convolution. However, depthwise convolution cannot fully utilize modern accelerators, hence it often runs slower. As a result, Fused-MBConv has more parameters and FLOPS compared with MBConv, but it also runs faster.
EfficentNetV2 vs EfficientNet
EfficientNetV2 was proposed by the same authors of EfficientNet three years later in the paper EfficientNetV2: Smaller Models and Faster Training. It uses a mix of MBConv and Fused-MBConv with smaller expansion ratio. In addition, Fused-MBConv is placed at the early stages to speed up the training. EfficientNetV2 also uses smaller kernel size and adds more layers to compensate for the reduced receptive field. EfficientNetV2 starts with the baseline network, EfficientNetV2-S, and scales up to EfficientNetV2-M/L.
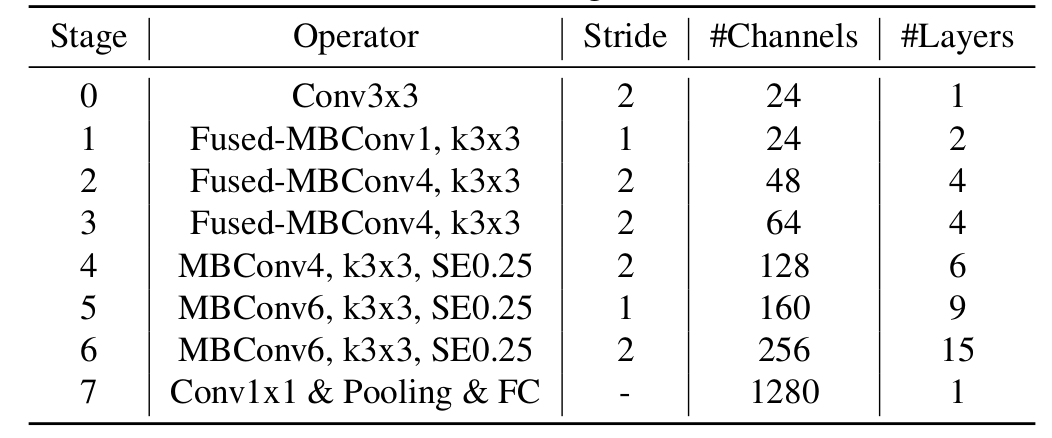
EfficeintNetV2 is trained with progressive learning to speed up training and maintain high accuracy. At early training epochs, the model is fed with small images and weak regularization. Then both image size and regularization strength are gradually increased during training. Progressive learning helps training converge faster and achieve higher accuracy.

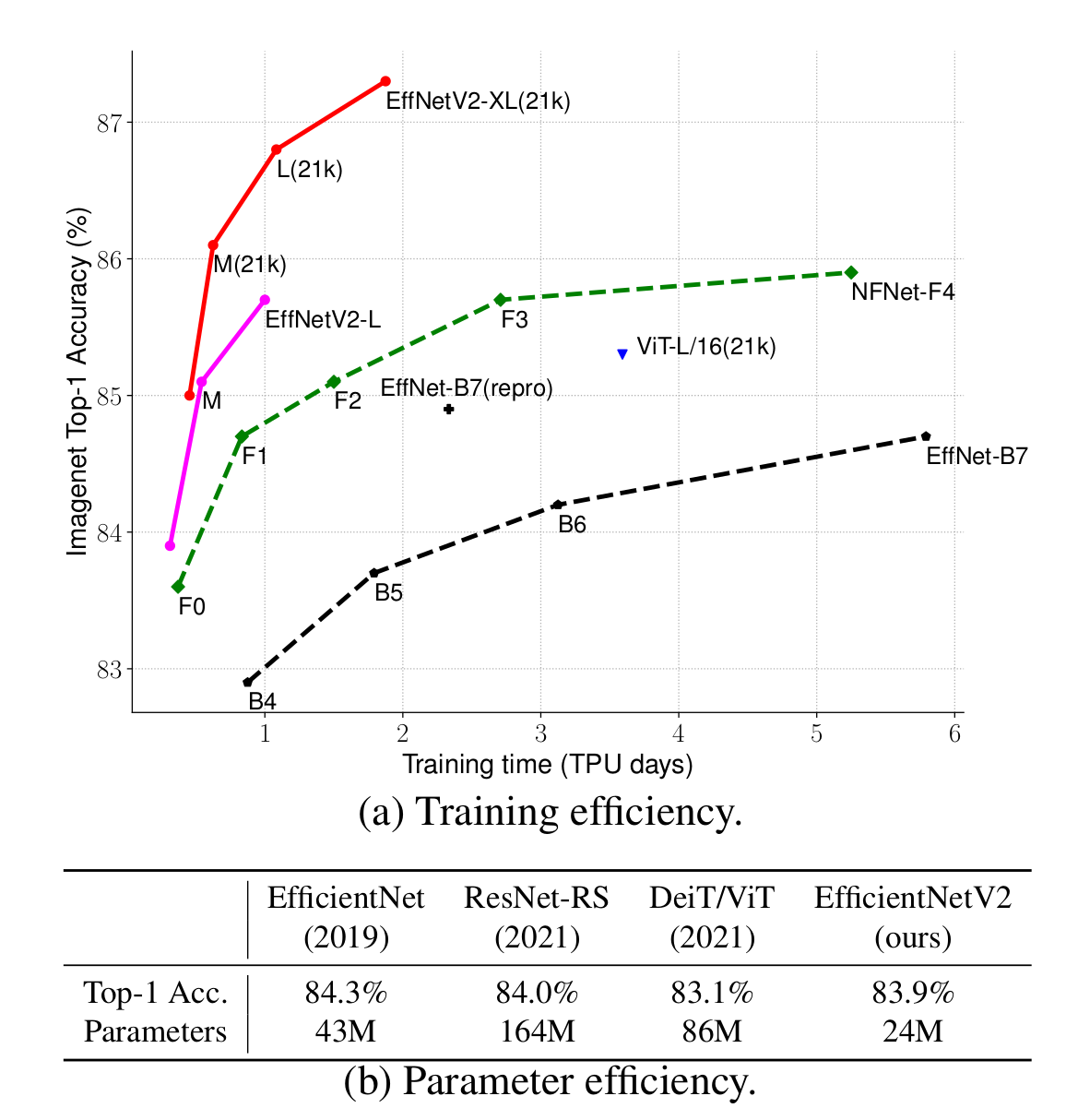
Compared with EfficientNetV1 and other state-of-the-art models, EfficientNetV2 achieves higher accuracy while being smaller and can be trained faster.


Member discussion