
Generation through Cycle Training

https://arxiv.org/abs/2305.14793
Authors: Zhuoer Wang, Marcus Collins, Nikhita Vedula, Simone Filice, Shervin Malmasi, Oleg Rokhlenko
Introduction
In this post we will talk about cycle learning strategy described in a recent paper as "Faithful Low-Resource Data-to-Text Generation through Cycle Training". We will discuss what it is, why we need it, how it improves model performance and we will see some applications to text generation.
Nowadays neural network generation models are achieving more and more high performance primarily due to pre-training on a large amount of data and model fine-tuning. However, we don't always have access to the labeled parallel data that is necessary for supervised learning, because it can be very expensive and time consuming. Besides, when we train in an unsupervised setting there appears to be an issue of consistency between data and text. Therefore the authors propose to introduce cycle training to solve to the main challenges:
- lack of training data (especially out-of-domain data)
- inconsistency between structured data and text
Cycle Framework
So what is a cycle framework? It consists of two models that are inverses of each other. One model is for generating text from data, and the other is for generating data from text.
Model
In the paper, the authors choose T5 as a backbone model for the both models of the framework. The T5 (Text-To-Text Transfer Transformer) is a pre-trained vanilla transformer introduced by Google. It has two main parts: encoder part and decoder part. The first component is a stack of encoders that takes an input sentence and generates a sequence of numbers. The second component is a stack of the same number of decoders, it takes as input the encoder's output and generates a text sequence – for example, a translated sentence.
Transformer is a model that uses the attention mechanism to capture dependencies between words in a sentence. In addition, it allows you to process all the words in the input sentence at the same time. Thus, this architecture is parallelizable and can be trained much faster than classical RNNs. As the model processes a word, it looks at the other words in the sentence using the self-attention mechanism and assigns more weight to those words that are associated with the input word.
Data
The input data is text and triplets (subject, predicate, object). So that both data-to-text and text-to-data models can be trained as sequence-to-sequence generation tasks.

Cycle Training
When training in a cycle framework, we freeze one model and backpropagate through the weights of the other to update them.
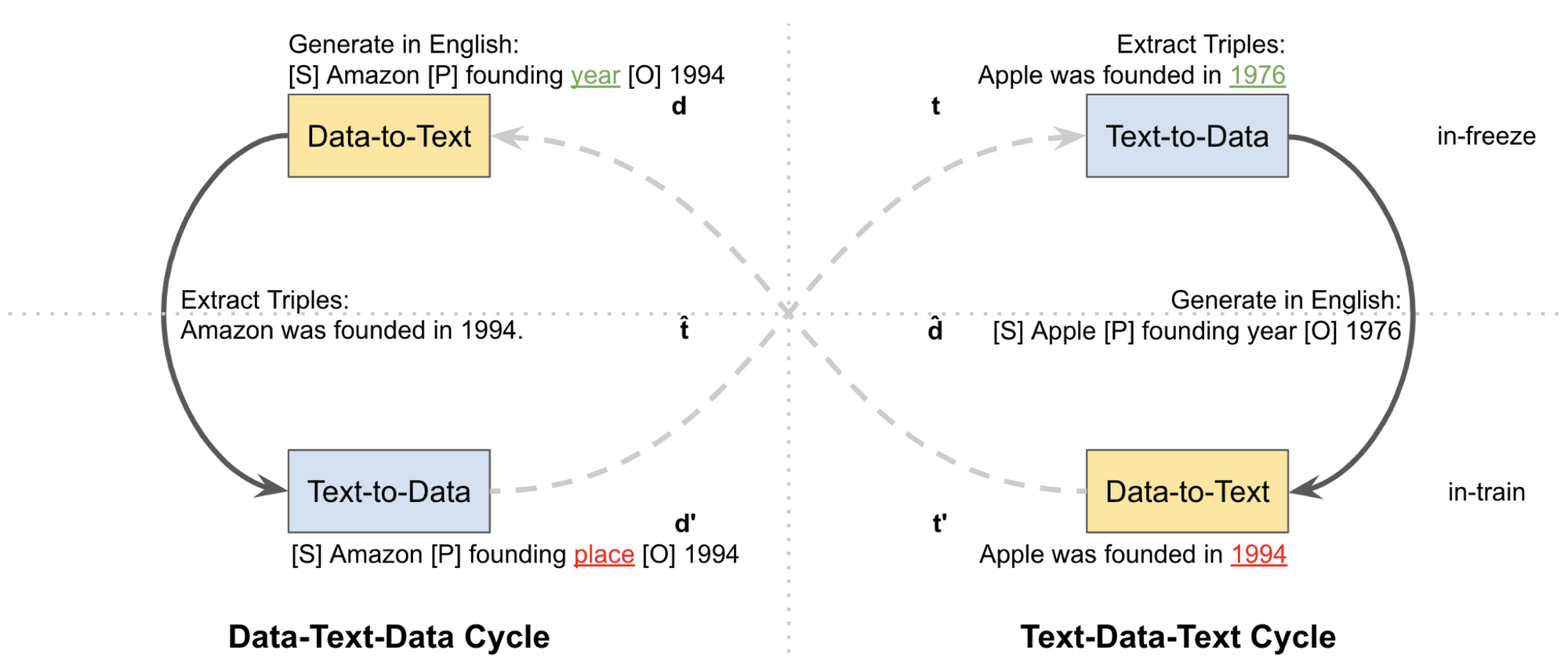
The cycle training consists of two main cycles:
- Data-Text-Data cycle that takes as input the linearized triplets, then it generates an intermediate output – text, and finally it reconstructs the data triplets from the predicted intermediate output sentences. It enforces the self-consistency of data.
- Text-Data-Text cycle that takes as input natural language text, from which it generates an intermediate output – triplets, and then the input sentence is reconstructed from the predicted intermediate structured data. It enforces the self-consistency of text.
Results
The cycle framework generation results are evaluated using the following metrics: ROUGE, BLEU, METEOR, PARENT, BERT-score. The WebNLG dataset was used for training and testing the model performance. It consists of data triplets and human written sentences. Also, the E2E dataset from the restaurant domain was used. It consists of human-annotated sentences and structured data. The results for the different model settings are presented in the table below. To see all the results, please check the paper https://arxiv.org/abs/2305.14793.
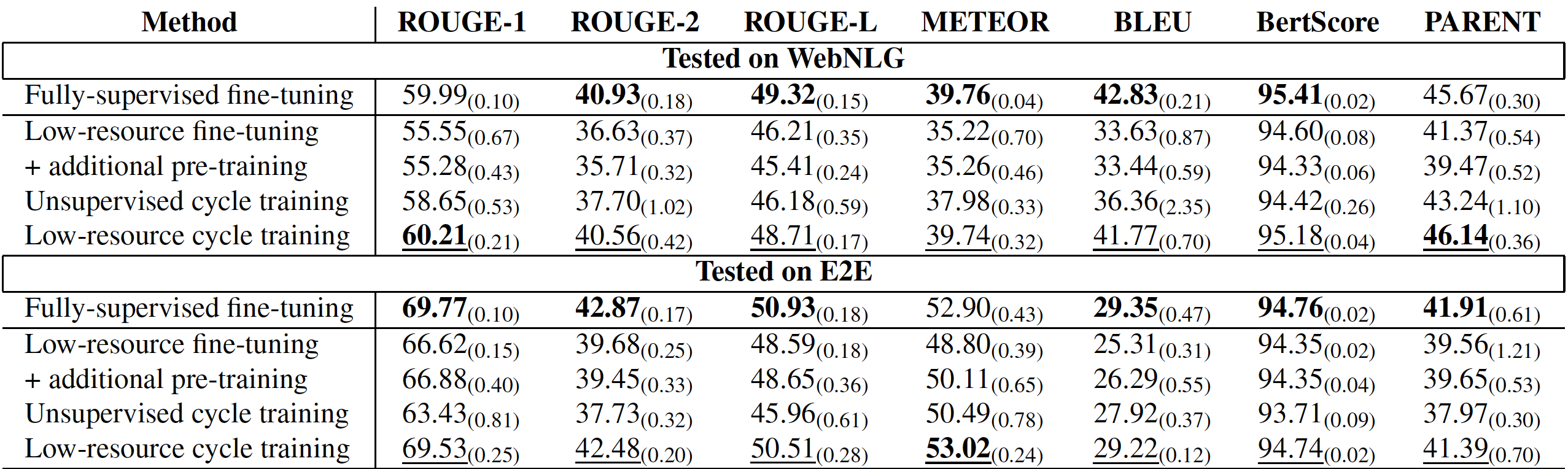
As you can see from the table, unsupervised cycle training usually does not perform as good as supervised training. However, when we have a small amount of annotated data for cycle initialization, then the unsupervised setting results are improved significantly in comparison with low-resource fine-tuning of the supervised method. It achieves competitive performance with the fully-supervised setting.
The table below shows you some generation and error analysis results.

Conclusion
In conclusion, cycle training has shown to be a very effective tool for data-to-text generation when there is a lack of annotated data. The low-resource cycle training using unsupervised strategy greatly improves the model generation results across different domains. Besides, there are fewer hallucinations and factual errors in the generated output in comparison with the supervised low-resource setting, resulting in increased faithfulness of the generated text.
References
- Wang, Z., Collins, M., Vedula, N., Filice, S., Malmasi, S., & Rokhlenko, O. (2023). Faithful Low-Resource Data-to-Text Generation through Cycle Training. arXiv preprint arXiv:2305.14793.
- Alammar J. The Illustrated Transformer. http://jalammar.github.io/illustrated-transformer/