
Unveiling SAM: Revolutionizing Image Segmentation with the Segment Anything Model

In the dynamic landscape of computer vision, the ability to accurately segment objects within images is a crucial task with wide-ranging applications. Traditional segmentation methods often struggle with the diverse array of objects encountered in real-world scenarios. However, a groundbreaking solution has emerged – the Segment Anything Model (SAM). In this blog post, we delve into the innovative approach of SAM and explore how it is reshaping the field of image segmentation.
Task
Promptable segmentation is an innovative feature introduced in the SAM that enhances the model's flexibility and adaptability by allowing users to provide textual or symbolic prompts to influence the segmentation process. The goal is to return a valid segmentation mask given any segmentation prompt. Unlike traditional segmentation methods that rely solely on visual cues from the input image, promptable segmentation empowers users to convey specific instructions, preferences, or constraints to guide SAM's segmentation output.
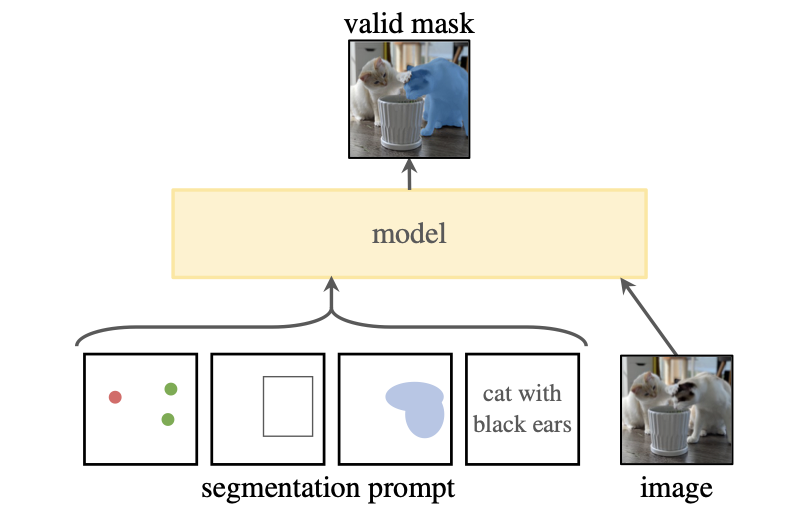
Multi-modal input leverages both visual and textual information, allowing users to provide textual prompts alongside images. It helps mitigate ambiguity by providing additional context and constraints for the segmentation task. Multi-modal input in the context of SAM involves integrating various types of data:
- Points: Users can provide point annotations to specify key landmarks or features within the image. These point annotations offer precise spatial information that can guide SAM's segmentation process, helping to identify object boundaries or regions of interest more accurately.
- Boxes: Box annotations define rectangular regions enclosing objects of interest within the image. By incorporating box annotations, SAM gains spatial context about the objects it needs to segment, facilitating more focused and localized segmentation predictions.
- Masks: Mask annotations provide pixel-level segmentation masks that delineate the boundaries of objects within the image. These masks offer detailed spatial information about object boundaries, enabling SAM to produce precise segmentation results that align closely with user-provided annotations.
- Text: Users can provide textual prompts or instructions to guide segmentation process. By incorporating textual input, SAM gains additional semantic context that complements the spatial information from visual annotations, enhancing its understanding of the segmentation task and enabling more informed segmentation decisions.
Model
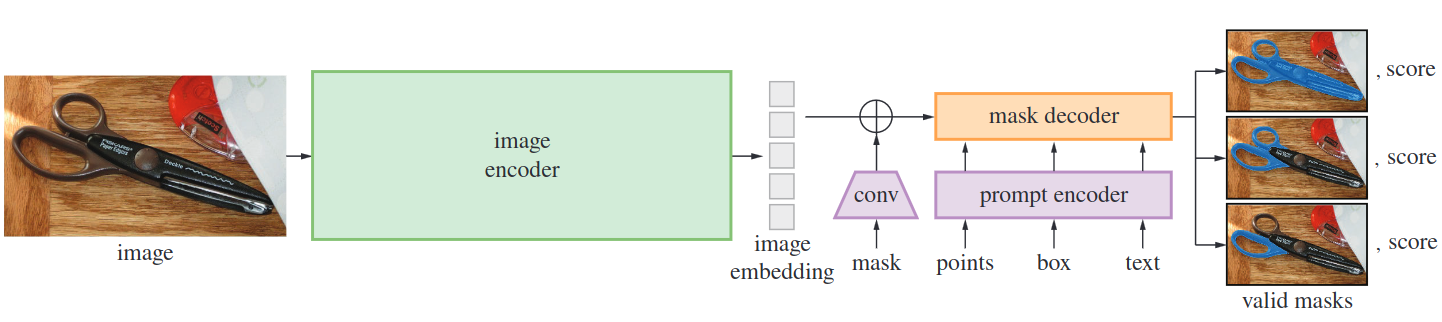
SAM consists of three main components: an image encoder, a prompt encoder, and a mask decoder. Drawing inspiration from Transformer vision models, SAM prioritizes real-time performance while retaining flexibility.
- Image encoder: The image encoder is responsible for processing high-resolution inputs efficiently, leveraging the MAE pre-trained Vision Transformer (ViT). This encoder allows SAM to scale effectively and benefit from powerful pre-training methods. It operates once per image and can be applied before prompting the model.
- Prompt encoder: For the prompt encoder, SAM considers two types of prompts: sparse (points, boxes, text) and dense (masks). Points and boxes are represented using positional encodings, combined with learned embeddings for each prompt type. Free-form text prompts are encoded using a text encoder. Dense prompts, such as masks, are embedded using convolutions and then added element-wise with the image embedding.
- Mask decoder: The mask decoder efficiently generates masks by mapping the image embedding, prompt embeddings, and an output token. SAM's decoder employs a modified Transformer decoder block, followed by a dynamic mask prediction head. Prompt self-attention and cross-attention mechanisms are utilized in two directions (prompt-to-image embedding and vice versa) to update all embeddings.
Data
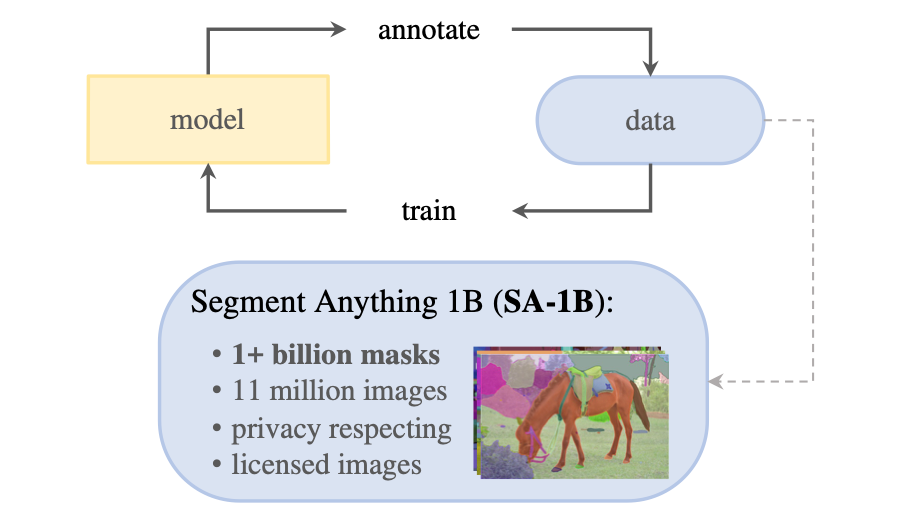
Created dataset the collection of 11million images and 1.1 billion masks. The data engine consists of 3 stages:
- A model-assisted manual annotation stage.
- A semi-automatic stage with a mix of automatically predicted masks and model-assisted annotation.
- A fully automatic stage in which the model generates masks without annotator input.
The dataset encompass a wide variety of object types, backgrounds, and environmental conditions to ensure the model's robustness and generalization capability. By training on rich and varied data sources, SAM aims to learn comprehensive representations that enable accurate segmentation of diverse objects in real-world scenarios.
Results
Experimental results demonstrate the effectiveness of SAM in segmenting a wide range of objects across different datasets. SAM achieves state-of-the-art performance on benchmark segmentation tasks, surpassing existing methods in terms of accuracy, robustness, and versatility. Qualitative and quantitative analyses further validate SAM's ability to produce accurate and semantically meaningful segmentations, even in challenging scenarios with complex object interactions and cluttered backgrounds.



Conclusion
In conclusion, the Segment Anything Model (SAM) presents a promising approach to address the task of object segmentation in images. By offering a unified framework capable of segmenting diverse objects across various domains, SAM provides a valuable tool for applications requiring accurate and versatile segmentation capabilities. Moving forward, SAM opens up opportunities for further research and application development in fields such as computer vision, robotics, medical imaging, and more.
References
- Kirillov, Alexander, et al. "Segment anything." arXiv preprint arXiv:2304.02643 (2023).


Member discussion