
Skeleton project with DWPose

Goal
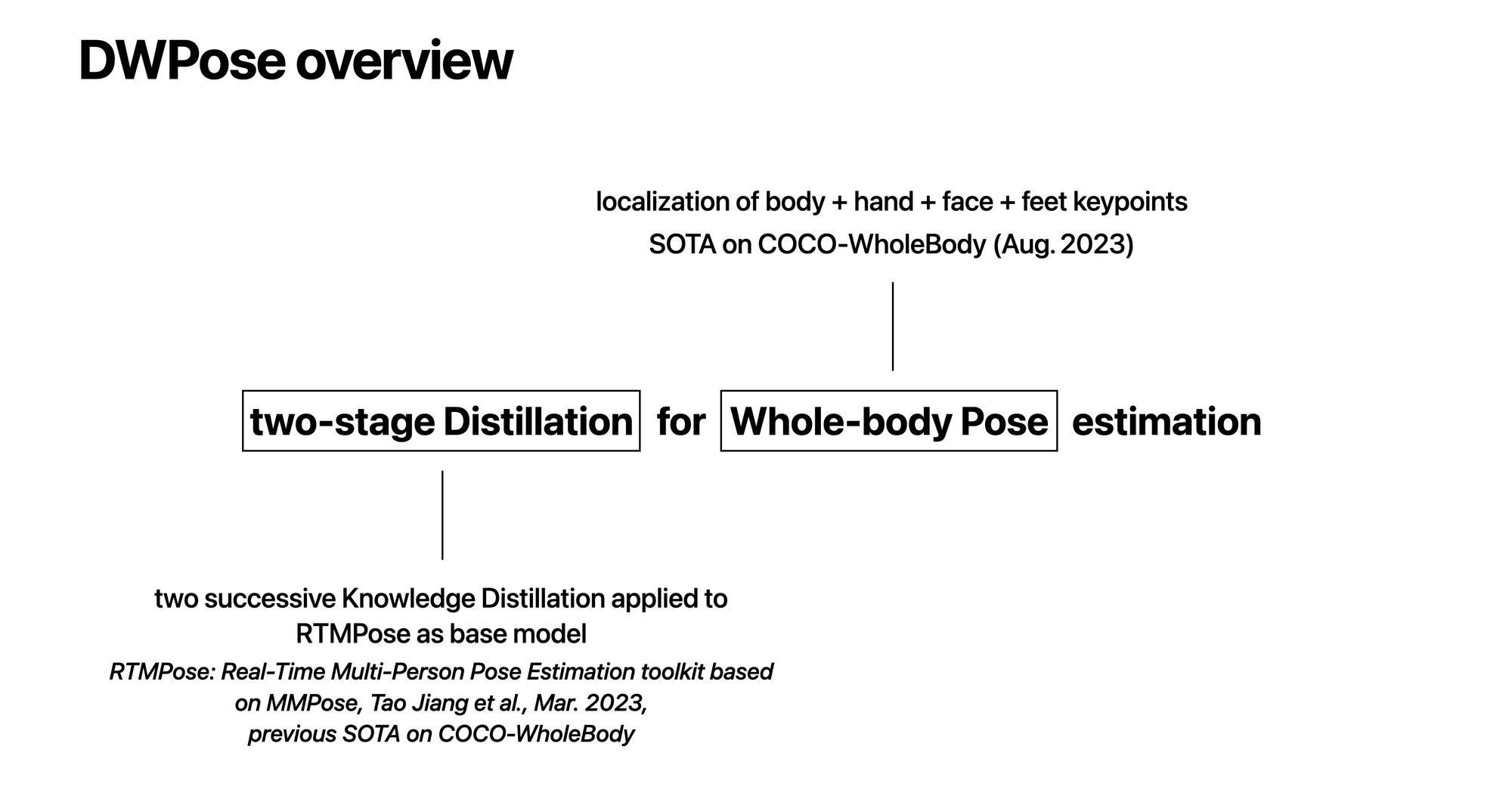
The goal of this project is to predict a user's keypoints in real time and guide them so that another AI can have the best possible images as input. Among the models we have studied for this problem, DWPose is the SOTA for 2D whole-body pose estimation (Aug. 2023), and represents an interesting solution for its accuracy while being lighter than competing models.

Whole-body Pose estimation
First, let's talk about the goal, challenges and usage of whole-body pose estimation.
The aim of whole-body pose estimation is to locate the body, face, hand and feet keypoints for all persons in an image simultaneously. It is important to note that this a different task from the human pose estimation (body-only keypoints).
It's a challenging task for the following reasons:
- compared to human pose estimation: much more keypoints to detect
- hierarchical structures of the body for precise keypoints localization
- fine-grained localization for low-resolution regions, especially face and hand
- multiple persons: complex body-parts matching
- data limitations : volume and diversity of data, especially for bodyparts scaling


The use cases are many and varied. Indeed, pose estimation has a crucial role in human-centric perception, understanding and generation tasks. OpenPose and MediaPipe tools are widely used, thanks to their convenience, although their performances remain unsatisfactory.
To conclude this section, a few words about related work:
- most previous models were designed for body-only, hand-only or face-only
- Previous SOTA for whole-body, RTMPose is a real-time model that suffers from some model designs and data limitations (lack of diverse hand and face poses)
Deploying a lightweight model
The precision and efficiency are essential for accurate, real-time results. In this section, we recall the Knowledge Distillation concept. It's a compression technique among other basic ones such as pruning and quantization.
Knowledge Distillation (KD) is a way to compress a model without compromising too much on accuracy. It enables a student to inherit knowledge from a larger trained teacher and thus enhances the efficiency of a compact model without extra-cost during inference.
Let's distinguish two types of distillation :

Two-stages Pose Distillation (TPD)
Now, let's describe how DWPose works.


Losses
For each stage and each type of distillation (feature or logit based), different losses are used to optimize the performance of the model.





Data
Performance depends on volume and diversity of data, especially for the different scales of body-parts. Besides COCO (118k train + 5k validation images), DWPose uses an additional dataset UBody that contains 1M frames from 15 real-life scenarios (an image every 10 frames)
Benchmarks and comparison with other models
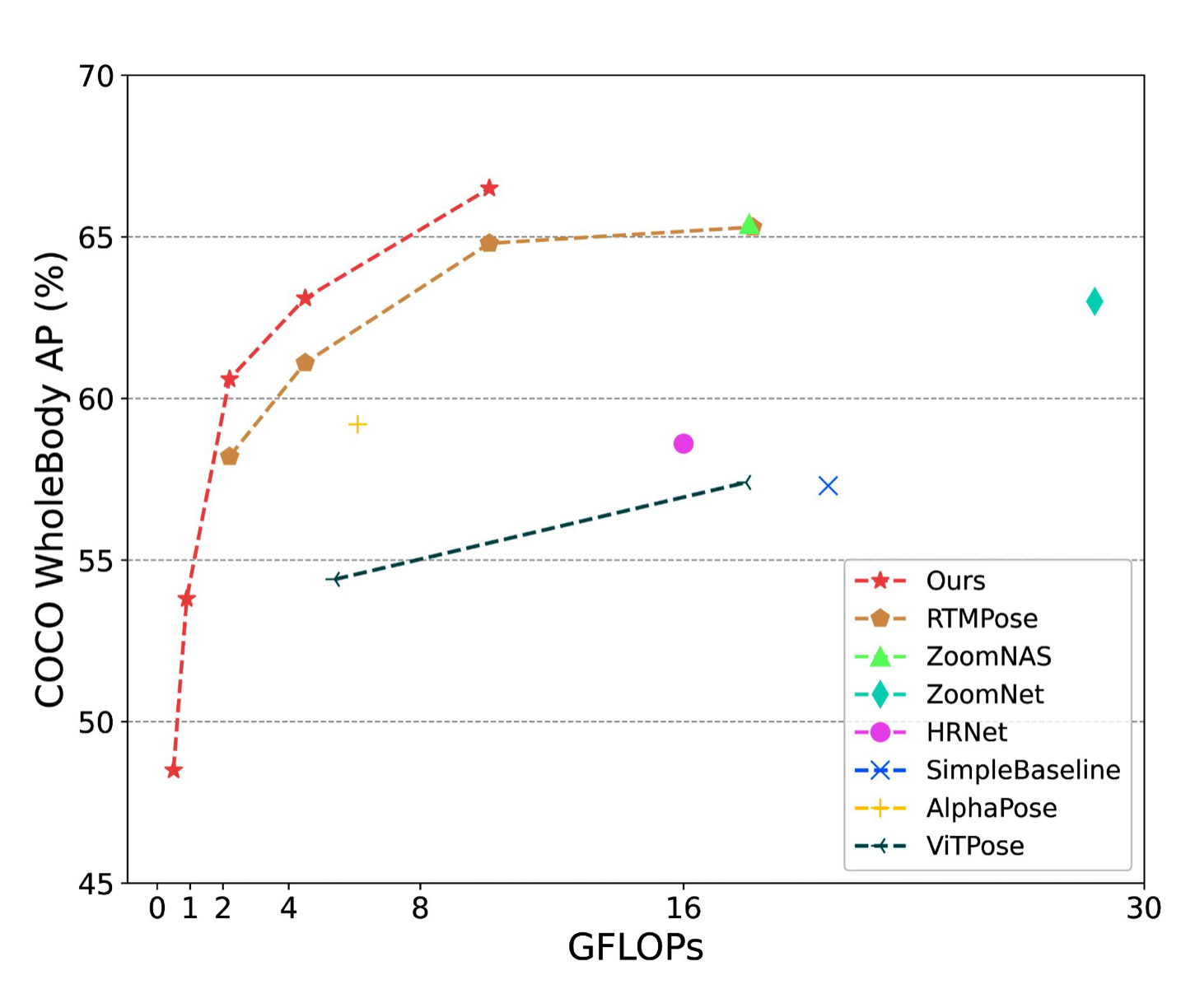
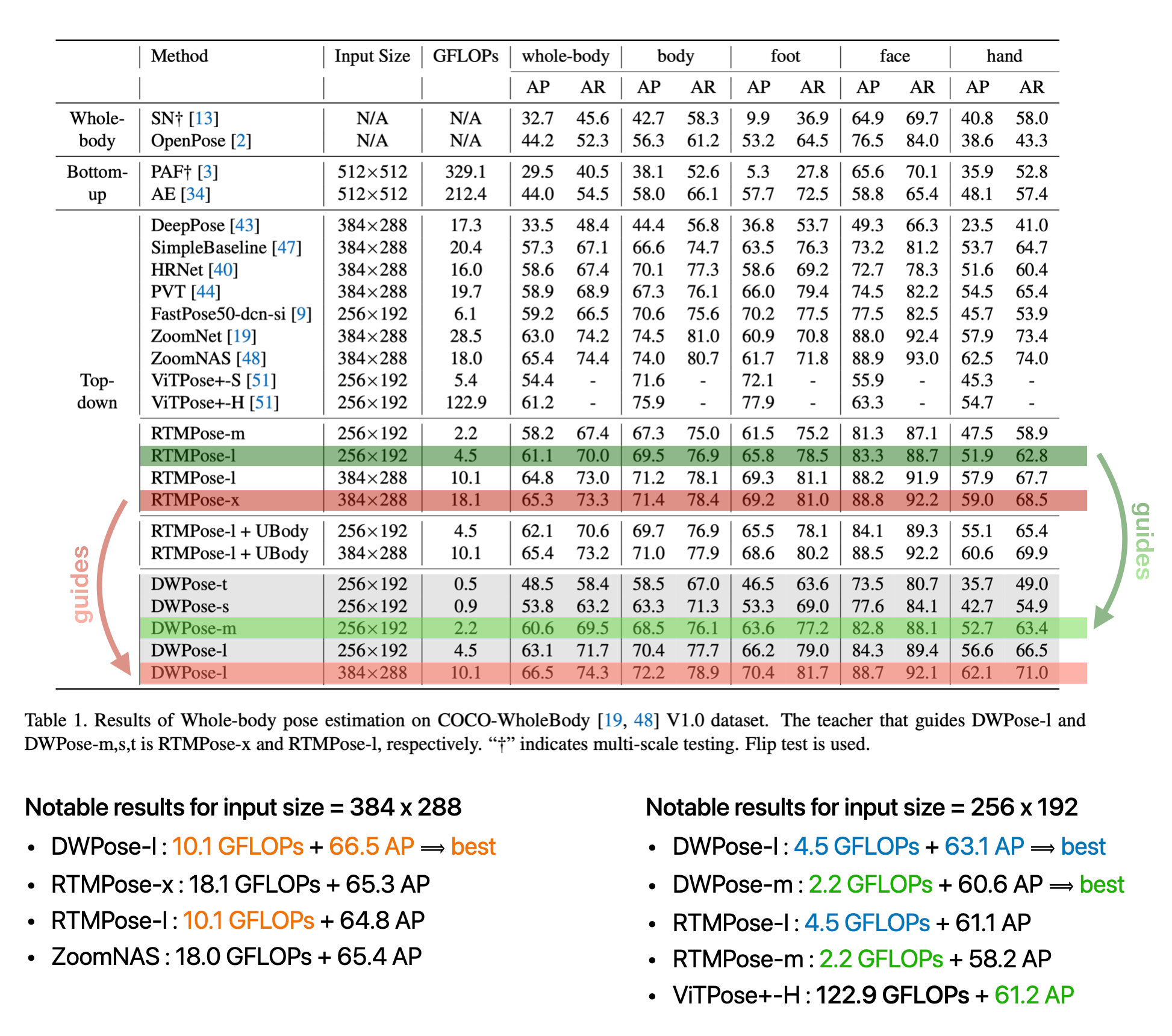



Benefits of TPD and UBody
- Using the extra dataset UBody in addition leads to considerable AP improvements, especially for hand detection.
- TPD further boosts the model’s performance.
- both distillation stages are beneficial for the students
- the combination results in performance improvements
Let's conclude with an interesting effect of the second-stage distillation.
Second-stage distillation can be applied when a better and larger trained teacher is lacking. Thus, it is possible to use the model itself as a teacher to improve it with a short training time since the second-stage only fine-tunes the head.


Member discussion