
SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery

Introduction
A large volume of remote sensing data is acquired through optical imaging sensors installed on artificial Earth satellites and aerial platforms. These methods have the advantage of providing realistic data in real time. Depending on the spectral ranges used for imaging, this data can be categorized into various types such as visible, infrared, ultraviolet, multispectral, hyperspectral, or SAR images. The study of remote sensing images has diverse applications across multiple fields. These include environmental monitoring and conservation, agriculture, disaster management, urban planning, infrastructure development, climate science, forestry, water resource management, geology, archaeology, and public health.
SuperYOLO Architecture
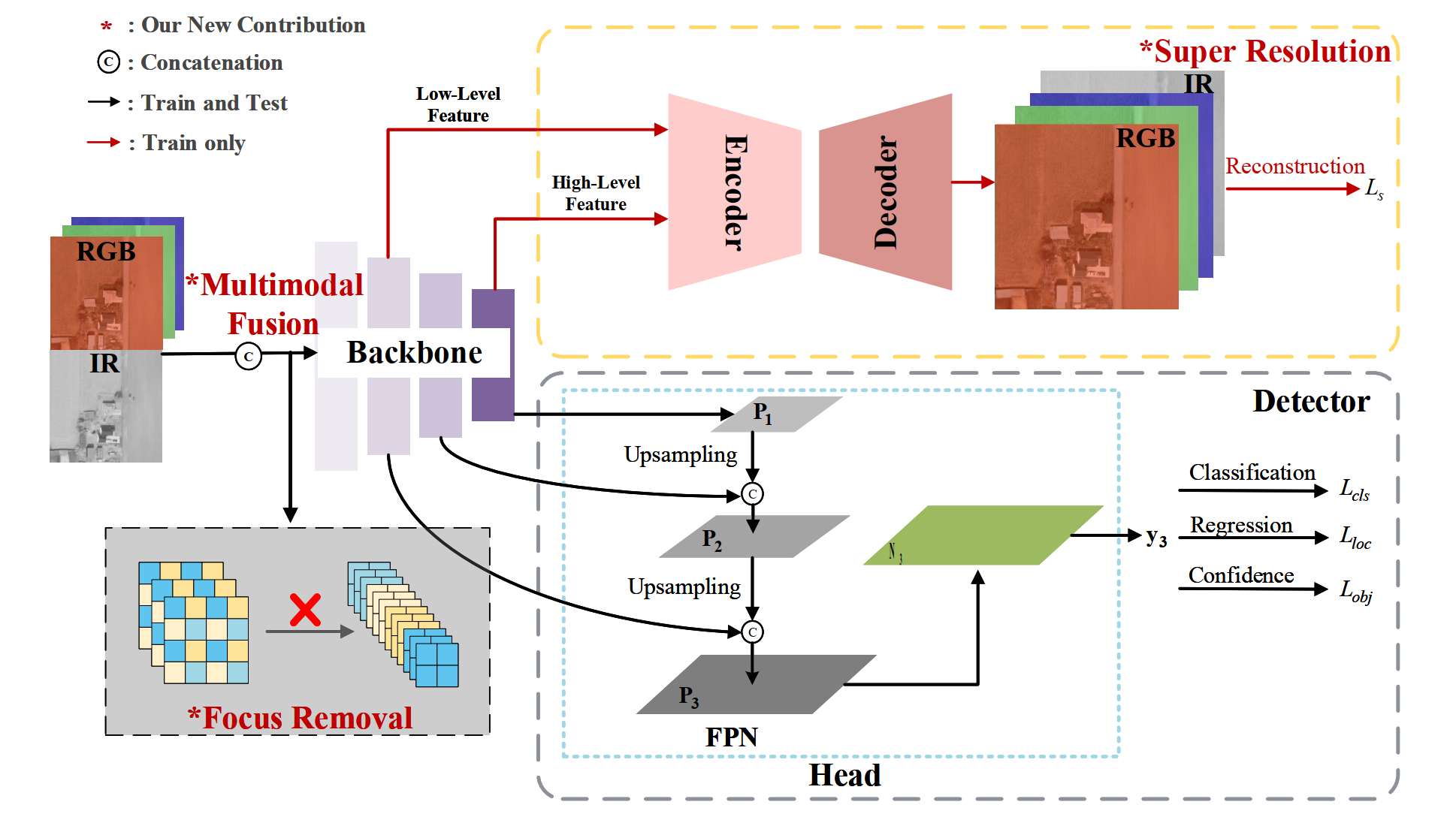
SuperYOLO is created using the YOLOv5 model as a baseline, the YOLOv5 network consists of two main components: the Backbone and Head (including Neck). The backbone is designed to extract lowlevel texture and high-level semantic features. Next, these hint features are fed to Head to construct the enhanced feature pyramid network from top to bottom to transfer robust semantic features and from bottom to top to propagate a strong response of local texture and pattern features. This resolves the various scale issues of the objects by yielding an enhancement of detection with diverse scales.
The SuperYOLO network architecture introduces three key enhancements. Firstly, the Focus module in the Backbone is replaced with a CBS module to prevent resolution degradation and subsequent accuracy loss. Secondly, various fusion methods are explored and optimized for pixel-level fusion for its computational efficiency in combining RGB and IR modalities to refine dissimilar and complementary information. Lastly, an assisted SR module is incorporated during training, which reconstructs HR images to guide Backbone learning in spatial dimensions and maintain HR information. During inference, the SR branch is omitted to avoid additional computation overhead.
Focus Removal: the YOLOv5 Backbone's Focus module partitions images spatially at intervals and then reconstructs them to resize the input images. This process involves collecting values for each pixel and reconstructing them to obtain smaller complementary images. However, the size of the rebuilt images decreases with the increase in the number of channels, leading to resolution degradation and spatial information loss for small targets. Given that the detection of small targets relies heavily on higher resolution, the Focus module is replaced with a CBS module comprising convolution operations to prevent resolution degradation. Additionally, the PANet structure and two detectors responsible for enhancing large-scale target detection are removed, as the main focus primarily lies on small objects in remote sensing scenarios.
Multimodal Fusion
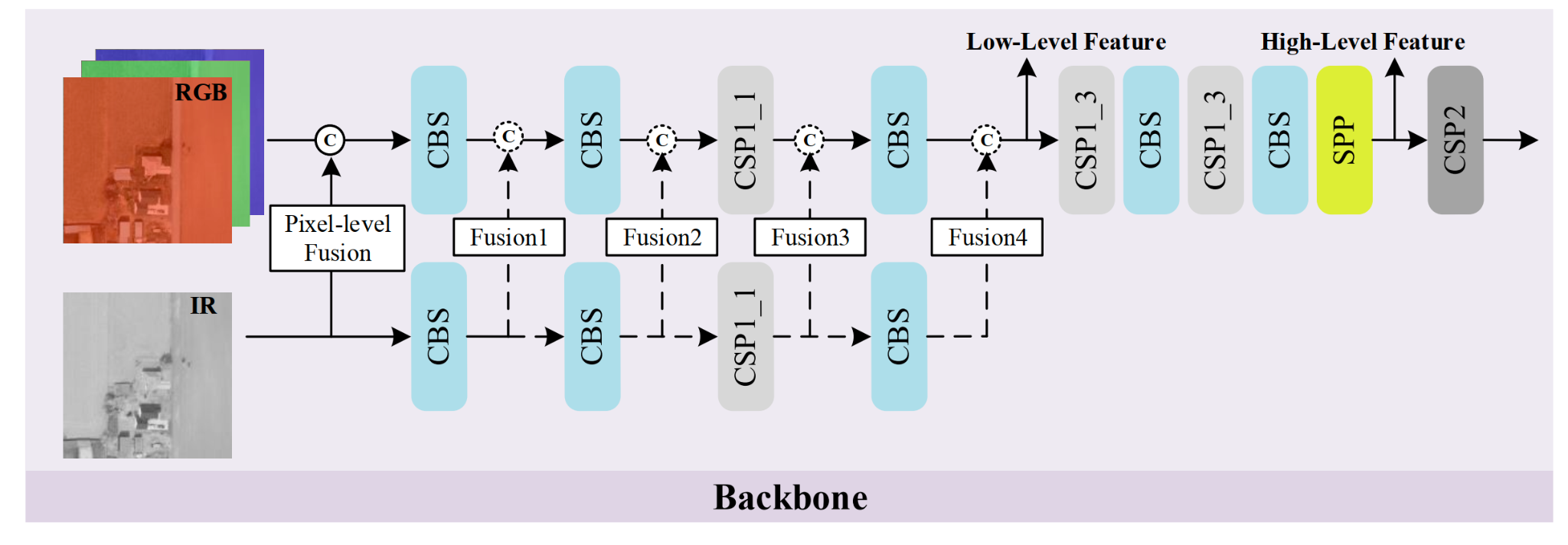
Multimodal fusion offers an effective approach to integrating diverse data from various sensors. There are three primary methods of fusion: decision-level, feature-level, and pixel-level, each applicable at different stages of the network. Decision-level fusion techniques merge detection outcomes in the final stage, often requiring significant computational resources due to repeated calculations across various multimodal branches. In remote sensing applications, feature-level fusion methods are predominantly utilized with multiple branches. Here, multimodal images are fed into parallel branches to extract independent features from different modalities, which are then combined using operations like attention modules or simple concatenation. However, the use of parallel branches can lead to repeated computations as the number of modalities increases, posing challenges for real-time tasks in remote sensing. Due to its significant computational requirements, decision-level fusion is not utilized in SuperYOLO.
Feature-level fusion involves merging different blocks, where the IR image is expanded to three bands for fair comparison. Fusion operations are performed in each block (fusion1, fusion2, fusion3, fusion4) with concatenation being the chosen method. In contrast, pixel-level fusion involves normalizing RGB and IR images to intervals of [0, 1], followed by concatenation. This approach requires lower computation compared to the other fusion methods, creating faster inference.
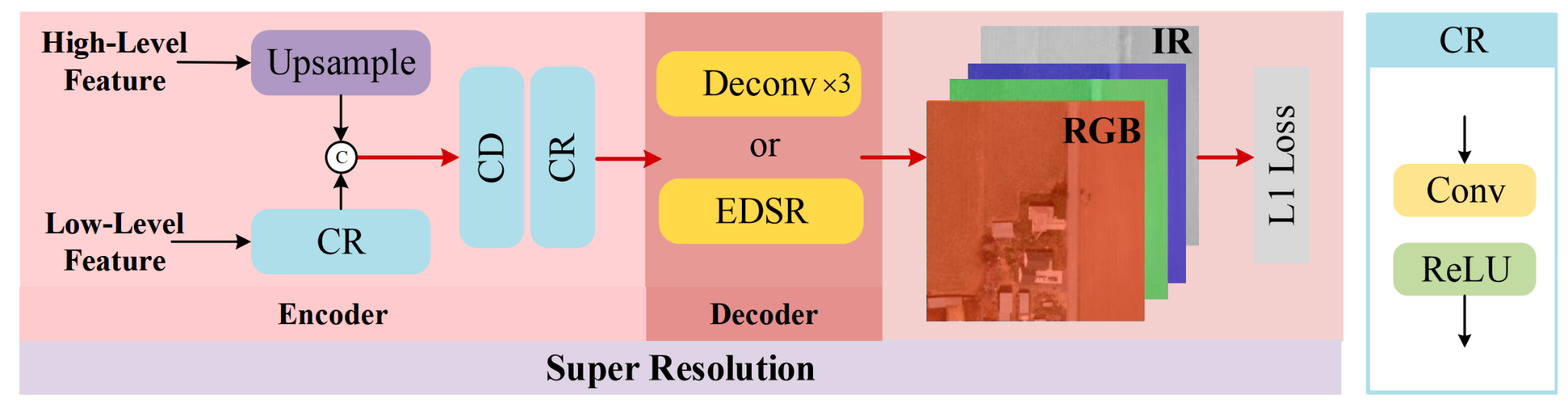
Super Resolution
The SR structure can be conceptualized as a basic Encode-Decoder model. Low-level and high-level features are selected from the backbone to integrate local textures and patterns and semantic information, respectively. As depicted in Figure 5, we choose the output of the fourth and ninth modules as the low-level and high-level features, respectively. In the Encoder phase, the low-level feature undergoes a Convolution-ReLU (CR) operation, while the high-level feature is upsampled to match the spatial size of the low-level feature. Subsequently, concatenation and two additional CR modules merge the low-level and high-level features. The CR module consists of a convolutional layer followed by ReLU activation. For the Decoder phase, the LR feature is upscaled to HR space, doubling the output size compared to the input image. The SR branch guides spatial dimension learning and transfers it to the main branch, thereby enhancing object detection performance. Additionally, we incorporate EDSR as our Encoder structure to evaluate SR performance and its impact on detection accuracy.
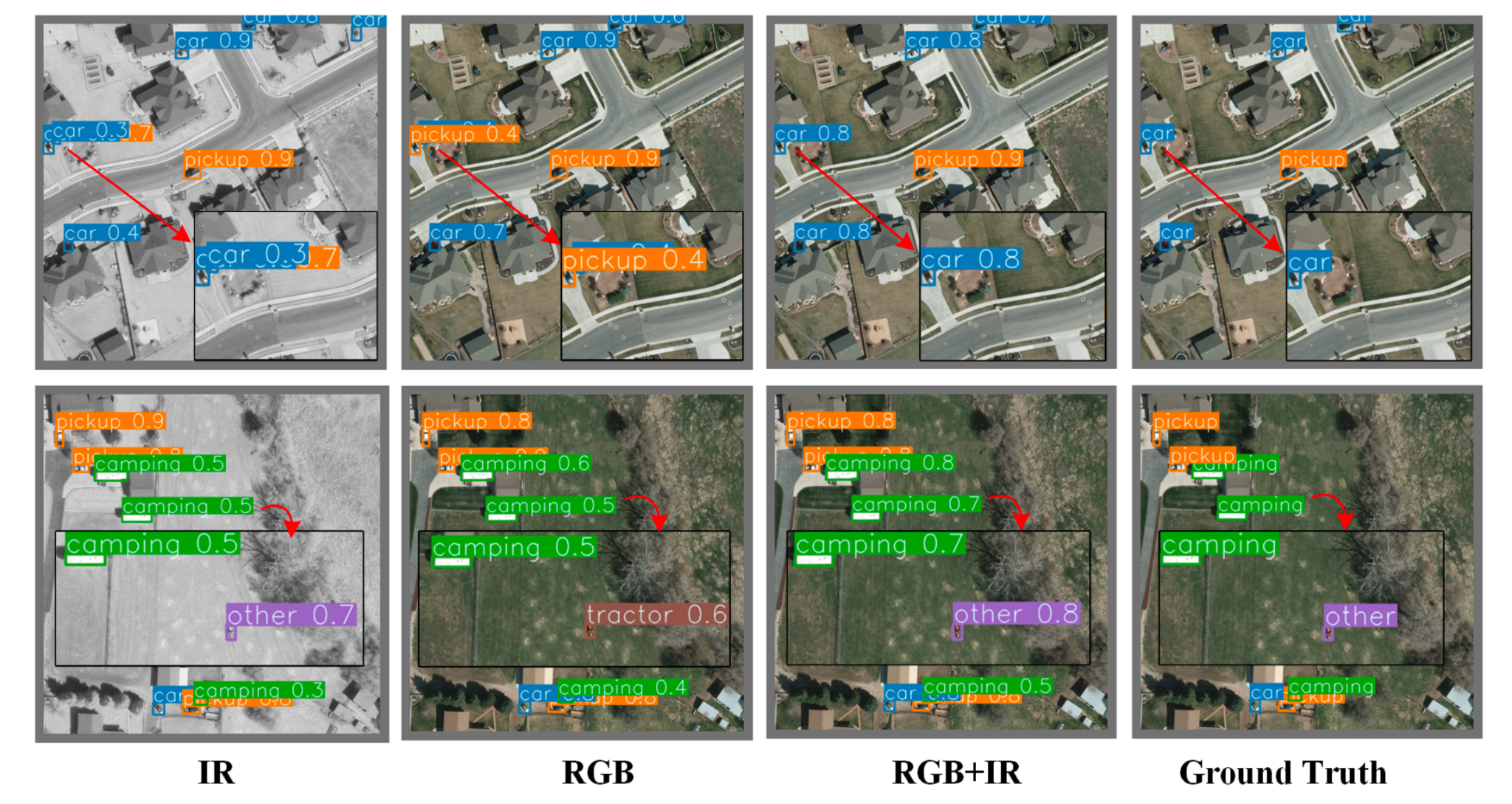
Performance Evaluation

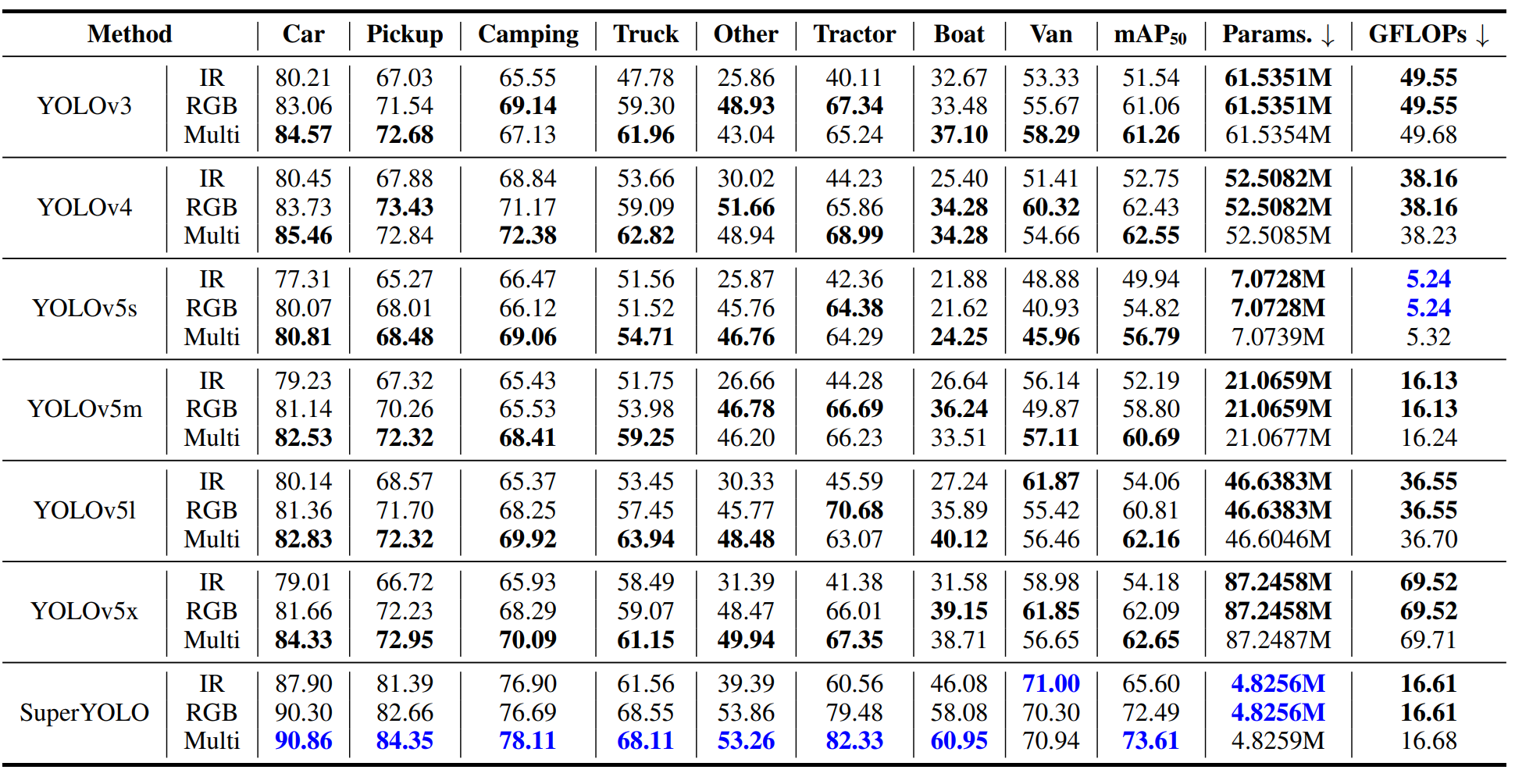
Conclusion
SuperYOLO, a real-time lightweight network that is built on top of the widely-used YOLOv5s to improve the detection performance of small objects in RSI. First, they have modified the baseline network by removing the Focus module to avoid resolution degradation, through which the baseline is significantly improved and overcomes the missing error of small objects. Second, they have conducted pixel-level fusion of multimodality to improve the detection performance based on mutual information. Lastly and most importantly, they have introduced a simple and flexible SR branch facilitating the backbone to construct a HR representation feature, by which small objects can be easily recognized from vast backgrounds with merely LR input required. We remove the SR branch in the inference stage, accomplishing the detection without changing the original structure of the network to achieve the same GFOLPs. With joint contributions of these ideas, the proposed SuperYOLO achieves 73.61% mAP50 with lower computation cost on VEDAI dataset, which is 16.82% higher than that of YOLOv5s, and 10.96% higher than that of YOLOv5x.
References:
Zhang, J., Lei, J., Xie, W., Fang, Z., Li, Y., & Du, Q. (2022). Superyolo: Super Resolution Assisted Object Detection in multimodal remote sensing imagery. IEEE Transactions on Geoscience and Remote Sensing, 61, 1–15. https://doi.org/10.1109/tgrs.2023.3258666


Member discussion