
High-Resolution Video Synthesis with Latent Diffusion Models
Introduction
Generative models have made remarkable progress in recent years, especially with the advent of techniques like generative adversarial networks (GANs), autoregressive transformers, and more recently, diffusion models (DMs). Among these, diffusion models offer distinct advantages in terms of robustness, scalability, and parameter efficiency. However, while the image domain has seen significant advancements, video synthesis has lagged behind due to computational costs and limited availability of large-scale datasets.
Main Idea
Our approach leverages Latent Diffusion Models (LDMs) to tackle high-resolution video synthesis. We propose a three-step process:
- Pre-train an LDM on images.
- Extend the LDM to handle videos by introducing temporal awareness through additional neural network layers.
- Fine-tune the model on encoded video sequences for enhanced performance.
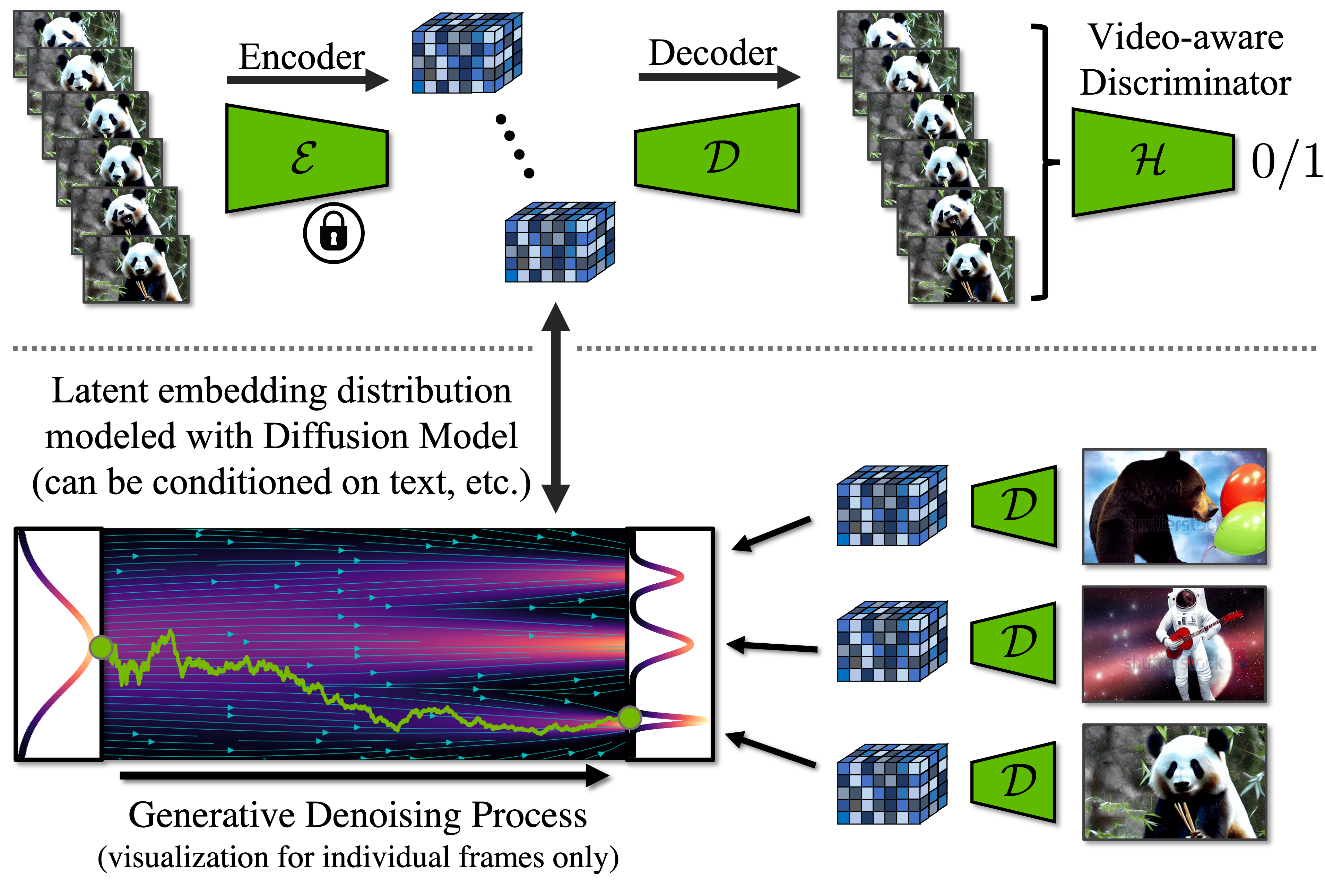
Latent Diffusion Models (LDMs)
LDMs utilize a compression model to transform input images into a lower-dimensional latent space. This compressed representation allows for efficient storage and reconstruction of high-fidelity images. By replacing the original data with its latent representation, LDMs significantly reduce parameter count and memory consumption while maintaining performance.
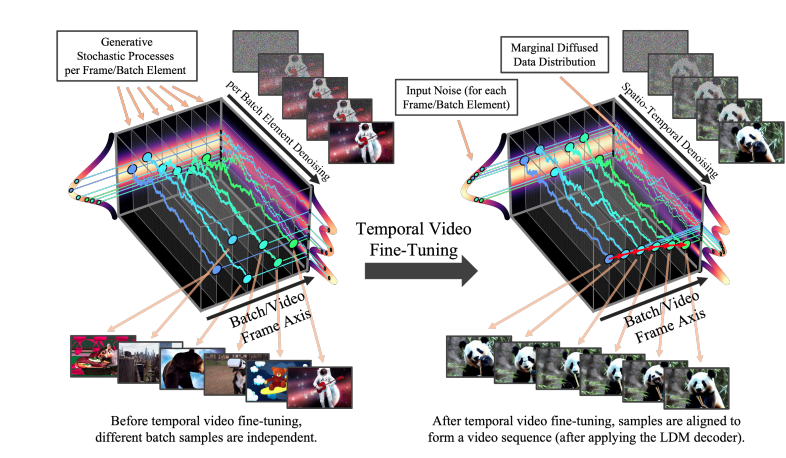
Latent Video Diffusion Models
To extend LDMs for video synthesis, we introduce additional temporal neural network layers to imbue the model with temporal awareness. This enables the generation of temporally consistent video sequences. Furthermore, we address the challenge of synthesizing very long videos by training prediction models with context frames and employing iterative sampling for long-form video generation.
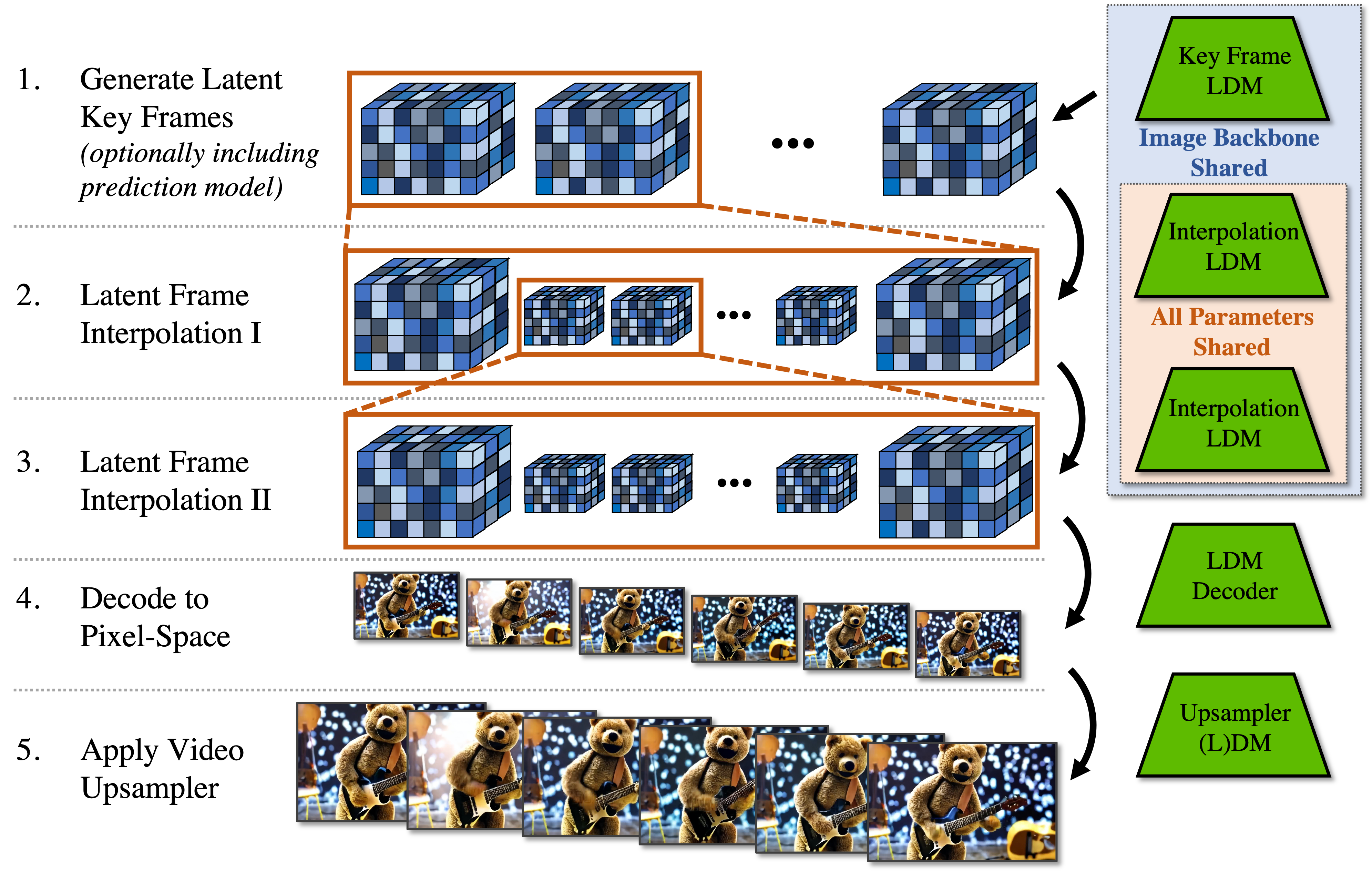
Interpolation of High Frame Rates
Achieving high-resolution video requires both spatial and temporal fidelity. To this end, we propose an interpolation method that generates intermediate frames between key frames. By leveraging masking-conditioning mechanisms, we ensure seamless interpolation while maintaining high quality.
Experiments and Results
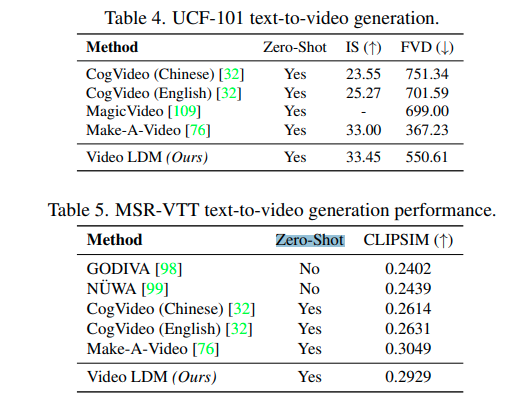
We conducted experiments on various datasets, including real driving scene videos and publicly available datasets like WebVid-10M. Our evaluation metrics include Frèchet Inception Distance (FID), Frèchet Video Distance (FVD), human evaluation, Inception Scores (IS), and CLIP Similarity (CLIPSIM). Results demonstrate the effectiveness of our approach in generating high-resolution, realistic videos.
References



Member discussion