
“Vision Transformer Adapters for Generalizable Multitask Learning”
https://arxiv.org/pdf/2308.12372.pdf This paper has been presented at the ICCV'2023 Conference.
Authors : D. Bhattacharjee, S. Süsstrunk and M. Salzmann. (IVRL & CVLAb, EPFL, Switzerland)
In this blog post, we will introduce a groundbreaking innovation - the first generalizable multitasking vision transformer adapters. These adapters are not just a leap forward in multitasking capabilities, but they also possess the ability to learn task affinities that can adapt to novel tasks and domains. If you want to delve deeper into the intricacies of this novel technology, you are in the right place!
Transformer adapters
First introduced for language tasks, adapters are trainable modules that are attached to specific locations of a pre-trained transformer network, providing a way to limit the number of parameters needed when confronted with a large number of tasks. The main idea of this is to enable transfer learning on an incoming stream of tasks without training a new model for every new task. With this technique, one can use already trained architectures (for e.g. Swin, DINO, etc) and refine it using adapters.
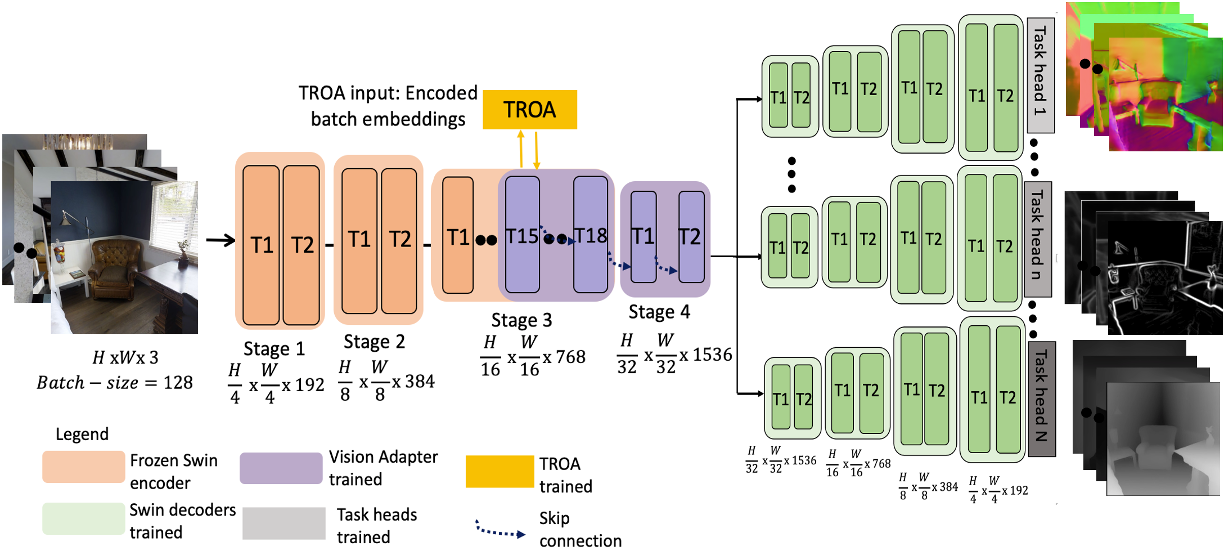
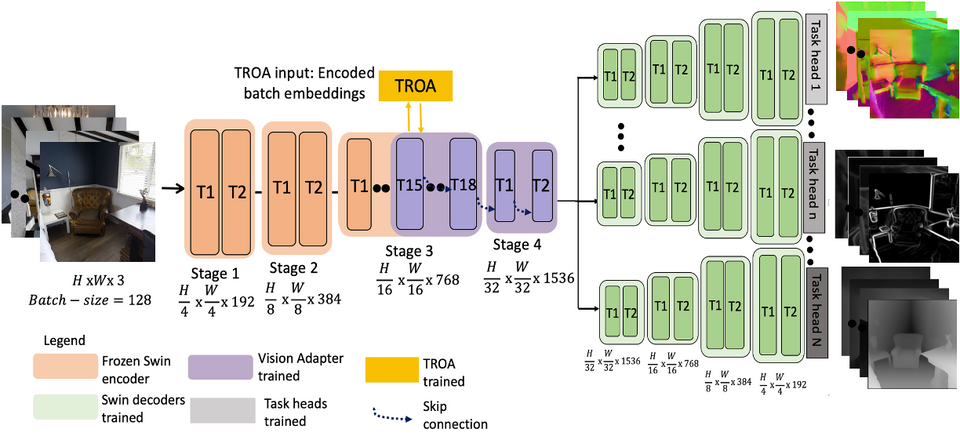
By replacing a part of the transformer layers in the backbone encoder, the objective of these adapters is to acquire diverse information types, crucial for multitasking, achieved through parameter sharing across all tasks. The proposed adapter relies on two main techniques: the Task Representation Optimization Algorithm (TROA), and the Task-Adapted Attention (TAA), both detailed below.
Task Representation Optimization Algorithm (TROA)
This algorithm introduced in the paper allows to measure the similarity between the different tasks we want to perform. Briefly, this algorithm calculates the cosine similarity between the different tasks' gradients, to finally create the tasks affinities matrix between all tasks. Proximate tasks (such as segmentation and edges prediction for example) should be more similar than non proximate ones (segmentation and normal surface estimation for example). These task affinities are then used by the novel task-adapted attention mechanism.
Task-Adapted Attention (TAA)
Within the framework of our adapters, the authors introduced a task-adapted attention mechanism. This attention mechanism cleverly combines gradient-based task similarities given from the TROA with self-attention usually applied in transformer architectures, from the image feature maps. The main trick behind the TAA is the use of the FiLM method [1], which will shift and rescale the task-affinities matrix output by TROA to the same dimension as the self-attention feature map to enable them to combine.
Multitasking results and comparison with other models
The results on different benchmarks are nothing short of extraordinary – not only does the method outperform existing convolutional neural network-based approaches, but it also surpasses the performance of other vision transformer-based methods for multitask learning.
The following table summarizes the quantitative results for different datasets and different tasks' settings. One major result to notice is that the more tasks we combine for learning, the better the results are. In detail:
- 60.80% of mIOU for Semseg when trained on 'S-D-N-E' (SemSeg, Depth, Normal and Edges) on the Taskonomy dataset, whereas it obtains 52.46% of mIOU for Semseg when the model is only trained on 'S-D' (SemSeg and Depth)
- 6.307 of RMSE for Depth when trained on 'S-D-N' on Cityscapes dataset, whereas it goes to 6.503 when only trained on 'S-D'.
The paper also highlights a better performance when the model has to generalize to unseen tasks and domains, as in Unsupervised Domain Adaptation configuration and Zero-shot task transfer. If you want to know more about this, we invite you to dig into the additional results provided in the paper.
Conclusion
- This paper well described how their novel adapters can be adapted to various transformer architectures in a parameter-efficient way making them volatile and practical.
- The results obtained confirm the benefits of task-adaptive learning for multitask learning, extending its utility to various settings such as zero-shot task transfer, unsupervised domain adaptation, and generalization without the need for fine-tuning.
- However, the authors deplore the extensive need of fully labeled datasets to obtain such performance. Indeed, in multitask learning, dealing with missing information (part of the label is not available) is a recurrent issue in real-life datasets. Future research focusing on this axis may be interesting.
References
[1] E. Perez, F. Strub, H. de Vries, V. Dumoulin, A. Courville, FiLM: Visual Reasoning with a General Conditioning Layer. https://arxiv.org/pdf/1709.07871.pdf