
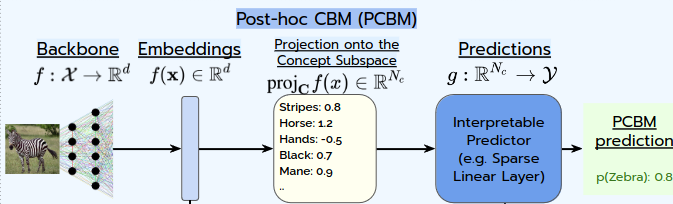
Post-Hoc Concept Bottleneck Models
Human vs machine decision-making
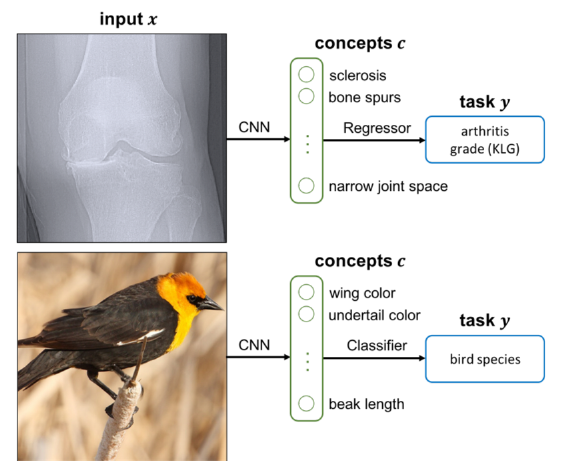
Neural networks are powerful tools, but their decision-making process is a black-box. Given an input, like an image, they make predictions based on the patterns they've learned from vast amounts of data. While these patterns capture some high-level features of the input, they may not always align with human understanding. Imagine a doctor diagnosing skin lesions. They wouldn't just look at the image and guess; they'd identify specific visual pattern, like a blue-whitish veil, to inform their diagnosis.
This concept-based approach is appealing for neural networks as well. Concept Bottleneck Models (CBMs) aim to achieve this by explicitly predicting human-interpretable concepts from which a final decision is made [1]. This approach offers a clear advantage: we can understand and explain the model's decision by examining the predicted concepts. However, training CBMs presents significant challenges in practice. First, they often suffer from a drop in performance compared with their black-box counterparts. Second, all training data must be densely-annotated with concepts, which is unfeasible in practice. These limitations are addressed by Post-Hoc Concept Bottleneck Models (PCBM) [2].
Post-Hoc Concept Bottleneck Models
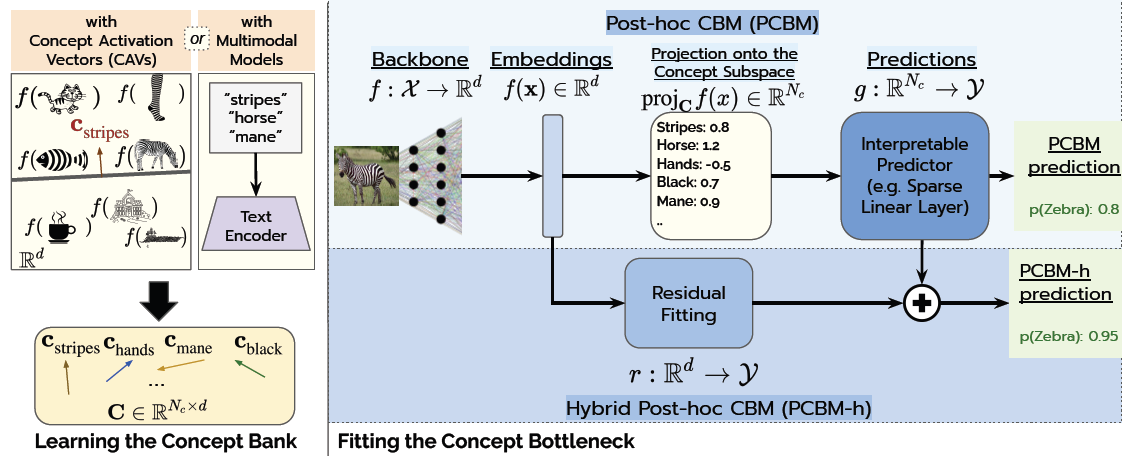
PCBMs can convert any pre-trained model into a more interpretable version, without sacrificing performance and using few concept-labeled data. They work in two steps:
- Concept Learning: First, a representation of predefined human-relevant concepts is learned. This can be achieved by training it to distinguish images with a specific concept from those without [3], or using multi-modal model to leverage natural language descriptions of concepts.
- Interpretable Prediction: Second, a simplified layer, called the bottleneck, is trained to make the final prediction based on the concepts detected on an input image. The resulting performance strongly depends on the chosen concept library, that should be expressive enough to capture the important information. To ensure the model maintains its original accuracy, PCBMs add a final step that captures any remaining details not captured by the concepts, similar to "filling in the gaps" with additional information.
Experiments
Authors experimented on various image datasets, including HAM10000, containing skin lesions, and CIFAR100. They showed PCBMs are able to recover original model performances and that their decision can be explained by analyzing concept importance. For instance in CIFAR1000, the most important concepts for the class Rose are flower, thorns and red. When diagnosing malignant skin lesions, the most important concepts for the PCBM align well with what doctor used, as they search for irregularities in the lesion.
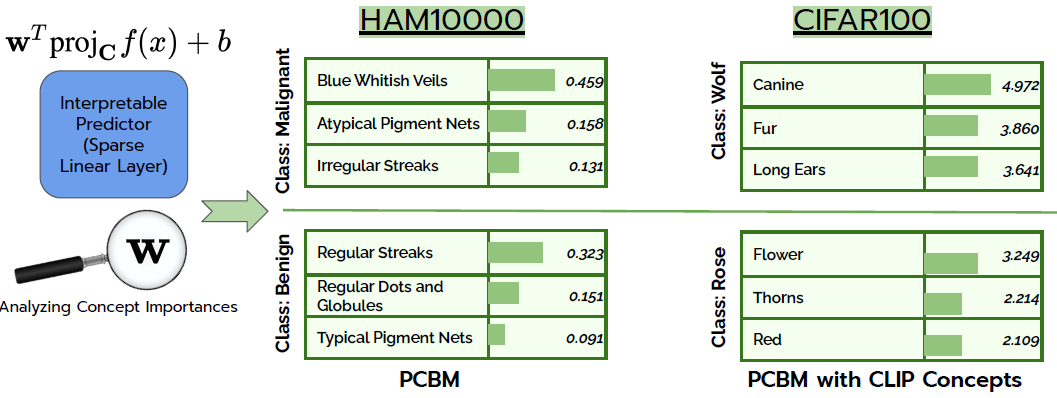
Finally, the global model behaviour can be easily improved. If a non-relevant concept (for a given class) is used, it can be pruned so that the model does not use it anymore to make its prediction.
References
[1] Koh, Pang Wei et al. (2020). “Concept bottleneck models”. International conference on machine learning. PMLR, pp. 5338–5348.
[2] Yuksekgonul, Mert, Maggie Wang, and James Zou (2023). “Post-hoc Concept Bottleneck Models”. The Eleventh International Conference on Learning Representations
[3] Kim, Been et al. (2018). “Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav)”. International conference on machine learning. PMLR, pp. 2668–2677.