
Mastering Generative AI with Large Language Models
In the rapidly evolving landscape of artificial intelligence, few advancements have captured the world's attention quite like Generative AI powered by Large Language Models (LLMs). These models have transcended mere algorithms to become the beating heart of transformative applications across various industries. Understanding their intricacies and harnessing their potential is now within reach, thanks to the course titled "Generative AI with Large Language Models" developed by DeepLearningAI in collaboration with AWS. This comprehensive course, hosted on Coursera, offers a fascinating journey into the realm of Generative AI, spanning approximately 15 hours of engaging content.
The course promises to equip learners with foundational knowledge, practical skills, and a functional understanding of how Generative AI works. It delves into the latest research on Gen AI, providing insights into how companies are leveraging cutting-edge technology to create unprecedented value. What sets this course apart is the instruction provided by expert AWS AI practitioners who are actively involved in building and deploying AI in real-world business use cases. It's a unique opportunity to learn from those who are at the forefront of AI innovation.
The Generative AI Project Lifecycle
The course outlines a structured approach to tackling Generative AI projects. It begins with defining use cases, a crucial step in understanding where and how Generative AI can be applied effectively. Next, participants learn to select pretrained models and relevant datasets, or even embark on the journey of pretraining their own model.
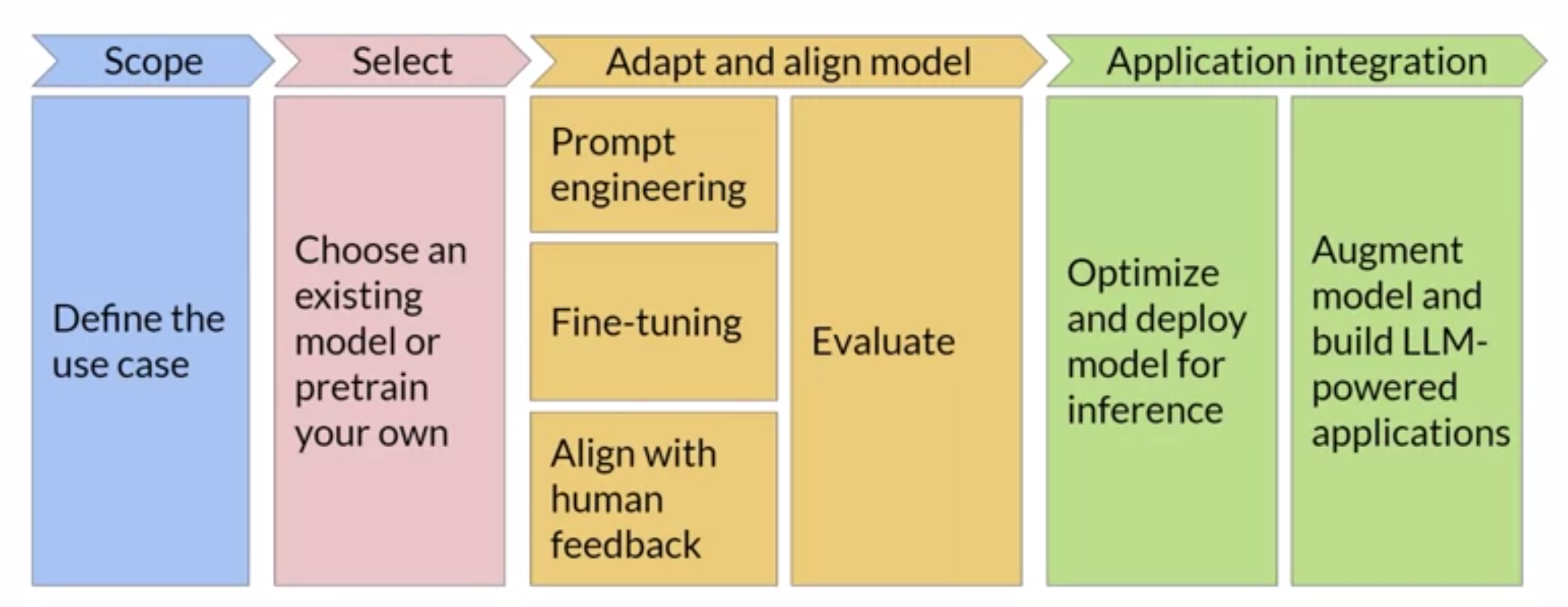
Prompt engineering is a critical aspect of Generative AI, allowing participants to fine-tune their models for optimal performance. This involves adjusting prompts and examples to align the model with specific tasks and human feedback. The course offers insights into various approaches, including zero-shot inference (no examples), one-shot inference (one example), and few-shot inference (a few examples). However, learners are reminded of the importance of context windows, which place limits on the amount of in-context learning that can be passed into the model. If model performance falls short with a higher number of examples, fine-tuning becomes the recommended solution.
Fine-Tuning Strategies
Fine-tuning Large Language Models, with billions of parameters, is a challenging task. Full fine-tuning presents a host of challenges, including memory constraints and the risk of catastrophic forgetting. To address these issues, the course introduces the concept of Parameter Efficient Fine Tuning (PEFT).
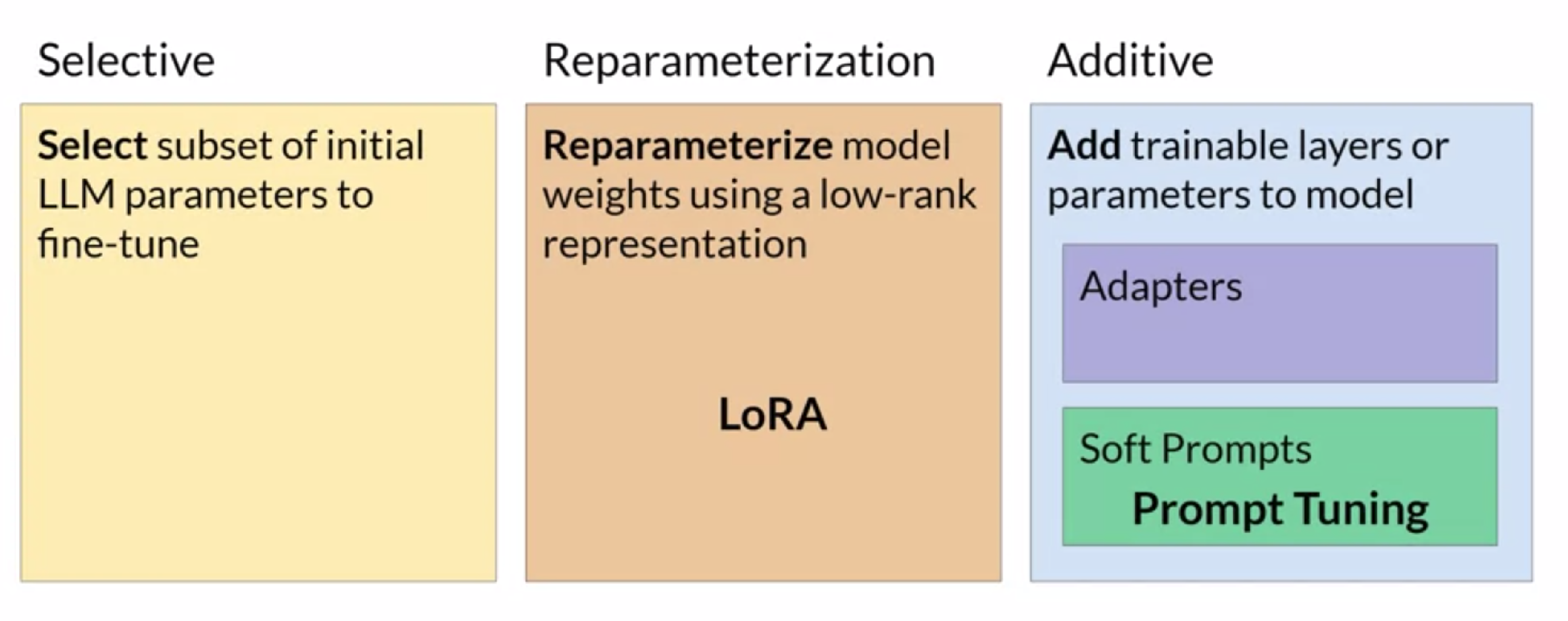
PEFT involves freezing the original model's weights and introducing new trainable layers with fewer parameters. This approach can fit on a single GPU and is less prone to catastrophic forgetting. Three main classes of PEFT methods are explored in the course:
- Selective Methods: These fine-tune only a subset of the original LLM parameters. However, the performance of these methods varies, and there are trade-offs between parameter and compute efficiency.
- Reparameterization Methods: These methods reduce the number of parameters to train by creating new low-rank transformations of the original network weights while keeping the original LLM parameters intact.
- Additive Methods: Fine-tuning is accomplished by keeping the original LLM weights frozen and introducing new trainable components. Two primary approaches are discussed: adapter methods and soft prompt methods.
LoRA: Low-Rank Adaptation of Large Language Models
Among the PEFT Reparameterization methods, LoRA stands out. It involves freezing the original LLM weights and introducing 2 rank decomposition matrices. During training, only the low-rank matrices are updated. During inference, the low-rank matrices are multiplied, and the result is added to the original weights. This approach allows you to train low-rank matrices for specific tasks and add them to the model when needed, minimizing memory requirements. LoRA offers a significant boost to LLM performance on specific tasks at a fraction of the cost compared to full fine-tuning.
Prompt Tuning: Another PEFT Gem
Prompt tuning, an additive PEFT method, is also explored in the course. Here, the original model weights are frozen, and input embeddings are manipulated by adding soft prompts (typically between 20 to 100) to the input embedding. These soft prompts are trained for each task. During inference, adding the corresponding soft prompt to the input embedding enhances performance while saving memory. Remarkably, prompt tuning can achieve performance levels on par with full fine-tuning, particularly when dealing with exceptionally large models.
Conclusion
The "Generative AI with Large Language Models" course by DeepLearningAI in collaboration with AWS is a treasure trove of knowledge for those eager to dive into the world of Generative AI. With expert instruction and practical insights into fine-tuning strategies like PEFT and methods like LoRA and prompt tuning, participants are equipped to unlock the full potential of Large Language Models and shape the future of AI applications. This course is a testament to the boundless possibilities that Generative AI offers and the critical role it plays in today's technological landscape.


Member discussion